
Software-defined Storage für File- & Object-Speicher
Wir sprachen mit Alfons Michels, Senior Product Marketing Manager über Datacores neuen vFilo (Distributed File and Object Storage Virtualization).
Im Bereich Software-defined Storage darf man Datacore zu den Pionieren zählen. Mit vFilo stellt der Hersteller eine neue Lösung vor, die ein ganz neues SDS-Kapitel aufschlagen soll.
 Alfons Michels, DatacoreMichels: Mit unserer Datacore One-Vision haben wir uns das Ziel gesetzt, den kompletten Bereich abzudecken, alle Datendienste und auch alle Konsumenten. Dazu gehören auch die Zugriffsarten: Bei strukturierten Daten geht man von Blockspeicher aus, unstrukturierte Daten werden im Regelfall über File und Object abgelegt.
Alfons Michels, DatacoreMichels: Mit unserer Datacore One-Vision haben wir uns das Ziel gesetzt, den kompletten Bereich abzudecken, alle Datendienste und auch alle Konsumenten. Dazu gehören auch die Zugriffsarten: Bei strukturierten Daten geht man von Blockspeicher aus, unstrukturierte Daten werden im Regelfall über File und Object abgelegt.
SANsymphony adressiert als Block-SDS vor allem strukturierten Unternehmensdaten. vFiLO steht für »Virtual File & Object« und ist SDS für File und Object. Es kann in Kombination mit Sansymphony eingesetzt werden, muss aber nicht.
Wir richten uns damit an die unstrukturierten Daten, wie Millionen von Dokumenten und multimedialer Objekte, verteilt über unzählige Speicher. In der Praxis ist es fast unmöglich etwas zu finden, ohne zu wissen, welcher Dateiserver oder welches NAS die Daten in welchem Ordner abgelegt hat.
Was bedeutet das genau?
Michels: Ziel ist es den Namensraums (Namespace) von diversen Dateispeichern zu konsolidieren, so dass die Dateien einfach auffindbar, zugreifbar und teilbar sind und gesichert werden können.
Dies schließt auch die Einbindung von Cloud-Speichern mit ein, als kostengünstige Alternative für die Archivierung selten genutzter Dateien oder als zusätzliche Kopie wichtiger Daten.
Wir skalieren quasi die existierenden Dateisysteme und verteilen die Lasten, um damit dem Wachstum unstrukturierter Daten zu begegnen. IT-Abteilungen lösen sich dadurch auch von der Bindung an einen der Storage-Hersteller.
Das heißt, vFilo sorgt für eine zentrale Verwaltung unstrukturierter Daten?
Michels: Wir etablieren einen globalen Namespace, der einen zentralen Zugriff erlaubt und protokollagnostisch erreichbar ist (NFS, SMB, S3). vFilo sorgt für eine automatische Lastverteilung über diverse Dateispeicher hinweg. Wir unterstützen so gut wie alle Hersteller, Dateisysteme und Protokolle. Die nötigen Regeln und Policies kann der IT-Manager flexibel und nach seinen Bedürfnissen festlegen. Das System prüft diese im Hintergrund permanent.
Suchanfragen werden global über alle gespeicherten Dateien hinweg ausgeführt, unter Berücksichtigung der Zugriffsrechte. Auch kann der Admin alle Dateien global administrieren.
Für welche Einsatzfälle eignet sich vFilo eher nicht?
Michels: Weniger gut eignet sich vFilo für kleinere und in sich abgeschlossen NAS-Umgebungen. Hier handelt es sich meist um ein preisempfindliches Umfeld das sich üblicherweise mit billigen und einfachen NAS-Fertiglösungen versorgt. Selbiges gilt für Unternehmen mit Cloud-First-Strategie oder Cloud fokussierten Anwendungsszenarien.
Auch ist vFilo nicht als nativer Objektspeicher gedacht. Wir nutzen die Möglichkeiten von Objektspeicherangeboten Dritter, lokal vor Ort oder in der Cloud für eine lange Datenhaltung.
Den meisten Mehrwert hat man im Hybrid-Cloud- und Enterprise-NAS-Umfeld, mit einer natürlich gewachsenen Infrastruktur vor Ort, die beispielsweise nicht ausgetauscht werden soll.
Wie muss man sich den Einsatz von vFilo in der Praxis vorstellen?
Michels: Unstrukturierte Daten sind überall verstreut, weder der Anwender, noch der Admin wissen, wo sie sich genau befinden. Werden Dateien verlagert, stört dies oft die Arbeitsabläufe, beispielsweise durch falsche Pfadnamen…
vFilo erlaubt die Assimilation existierender Dateiserver in ein virtuelles Scale-Out-NAS – und dies binnen Minuten. Wir lesen bei der Implementierung nur die Metadaten ein, die Daten selbst bleiben unangetastet. Auch die Datei-Attribute bleiben alle erhalten.
Daraus entsteht ein durchsuchbarer und skalierbarer Katalog, der Anwendern und Administratoren einen globalen Zugriff erlaubt, ohne Protokolleinschränkungen. Die Nutzer müssen nicht mehr wissen, auf welchem Speicher die Daten abgelegt sind.
Anhand der Metadaten werden Regeln festgelegt, damit die verfügbare Kapazität optimal und kostensparend genutzt wird. Es erfolgt eine transparente Lastverteilung im Hintergrund. Das heißt, vFilo legt die Daten automatisch dort ab, wo sie den festgelegten Anforderungen am ehesten gerecht werden. Mögliche Kategorien für die Speicher sind zum Beispiel Leistung, Hochverfügbar, günstig oder Cloud.
Inaktive Dateien kann das System vom Primary-Storage beispielsweise global dedupliziert und komprimiert auf einen günstigen Speicher auslagern. Dies lässt sich Share-by-Share oder File-by-File durchführen. Bei Bedarf bleiben wichtige Daten unangetastet auf dem primären Speicher. Wird eine ausgelagerte Datei häufiger angefordert, wird sie wieder aktiv und gegebenenfalls, gemäß er Policys, auf den Primärspeicher zurückgeholt. Das verbessert natürlich die Performance sowie die Effizienz.
Dies gilt auch für die Cloud?
Michels: Ja, die Datenhaltung kann auch auf die Cloud und genauso transparent ausgedehnt werden, zum Beispiel als Erweiterung der lokalen Kapazität. Es lassen sich diverse Storage-Architekturen assimilieren, wir unterstützen sowohl Dell EMC, Google, Netapp, Cloudian, Microsoft Azure, Amazon AWS und eben alles mit S3.
vFilo arbeitet standortübergreifend und lässt sich auf mehrere Sites anwenden und verbindet Zweigstellen, die Unternehmenszentrale oder auch einen Außen-Campus.
Welche Voraussetzungen sind für vFilo nötig?
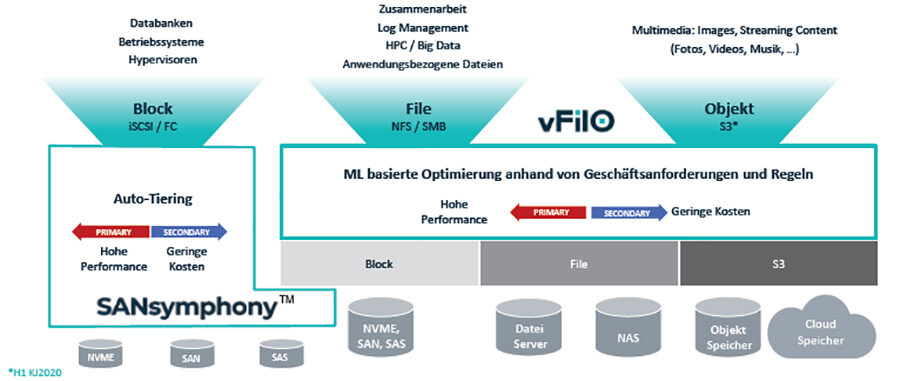 Erweitertes Datacore SDS-Portfolio (Grafik: Datacore)Michels: Generell handelt es sich um eine Vor-Ort-Installation. Generell geht es einmal um die Metadaten und um die Datendienste. Sprich, was mach ich mit den Daten.
Erweitertes Datacore SDS-Portfolio (Grafik: Datacore)Michels: Generell handelt es sich um eine Vor-Ort-Installation. Generell geht es einmal um die Metadaten und um die Datendienste. Sprich, was mach ich mit den Daten.
Die Metadaten werden separat in einem hochverfügbaren Cluster gehalten. Hierzu kann man jeden beliebigen Server verwenden, wie auch eine virtuelle Maschine (VM). Getestet ist die Lösung für 200 Millionen Files, um eine Hausnummer zu nennen. Dies benötigt aber die Unterstützung der Hardware. Daher sind die Mindestanforderungen an Compute-Power, Arbeitsspeicher etwas höher als bei Sansymphony. Mögliche Änderungen müssen schnell verarbeitet werden, daher sind SSDs unabdingbar.
Bei Object-Storage lässt sich zwar gut nach oben in punkto Kapazität skalieren, aber weniger bei der Leistung.
Michels: Das ist richtig, wir beginnen daher zunächst mit File. Object unterstützen wir nach oben hin erst im nächsten Jahr. Nach unten hin nutzen wir den Objekt-Store natürlich bereits. Dies ist auch von Kundenseite klar gefordert, weil Cloud oder lokaler Objekt-Speicher ihnen eine flexible Skalierbarkeit bietet und oft auch günstigere Kosten zur Langzeitdatenhaltung.
vFilo kann zwar in naher Zukunft auch Objekte zu den Anwendungen und Nutzern präsentieren, wir sind aber keine native Objektlösung. Wir nutzen die SDS-Mechanismen auf File-Ebene auch für die Objekt-Speicher. Mit den Metadaten erfüllen wir aber die Anforderungen des Object-Stores. Aus File-Sicht separieren wir die Metadatenebene. Die Data-Mover sind frei skalierbar, nach oben, wie nach unten. Die Lizenzierung ist auch nicht davon abhängig.
Wie berechnet sich die Lizenzierung von vFilo?
Michels: Die Lizenzierung von vFilo basiert auf der genutzten Kapazität in TByte. Dabei wird unterschieden zwischen aktiven Daten auf Primärspeichern und inaktiven Daten, die dedupliziert und komprimiert auf Objekt- und Cloud-Speichern liegen. Möglich sind eine 1- und 3-Jahres-Subskription inklusive Support. Das Bestellminimum liegt bei 10 TByte und skaliert ab da in 1-TByte-Schritten.
- keine manuelle Dateiverlagerung mehr
- keine Unterbrechung durch Dateimigration
- einheitliche Verwaltung unterschiedlichster Dateitypen und -Profile innerhalb eines Systems
- automatische Daten-Optimierung spart Platz und reduzierte Kosten bei gleichzeitiger Erreichung von Leistungs- und Verfügbarkeits-Zielen
- Undelete Funktion erlaubt RPO von Null
- Regelbasierte, autonome Live-Daten-Tiering- und Mobilitätsfunktionen
- Dateigranulare Snapshots, Clones, Replikationen und Wiederherstellung
- Erweiterbare Metadaten für Tagging, Klassifizierung und kundenspezifische Beschreibung
- Globale Daten-Deduplizierung und -Kompression, In-Flight und At-Rest für Cloud und Object-Storage