
Gegen das Datenchaos: Vom Data Lake zum Data Hub
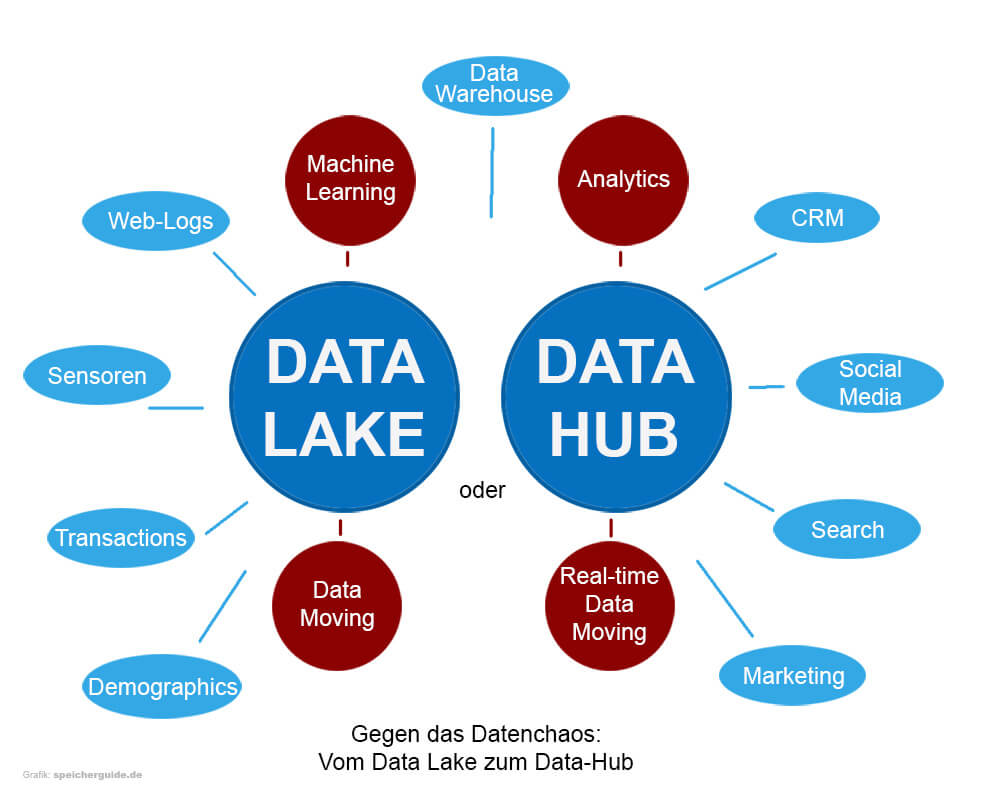 Gegen das Datenchaos: Vom Data Lake zum Data-HubGegen das Datenchaos: Vom Data Lake zum Data Hub – Lange waren SQL-Datenbanken, Data-Warehouses und kleinere Data-Marts das Herz der Unternehmens-Datenverarbeitung. Dann betrat der Data Lake zusammen mit der In-Memory-Technologie Hadoop die Bühne. Das war etwa 2010.
Gegen das Datenchaos: Vom Data Lake zum Data-HubGegen das Datenchaos: Vom Data Lake zum Data Hub – Lange waren SQL-Datenbanken, Data-Warehouses und kleinere Data-Marts das Herz der Unternehmens-Datenverarbeitung. Dann betrat der Data Lake zusammen mit der In-Memory-Technologie Hadoop die Bühne. Das war etwa 2010.
Realisiert werden Data Lakes innerhalb des Unternehmens beispielsweise mit Hardware von Isilon (heute zu Dell EMC gehörig). Als Cloud-Variante hat Amazon S3 die längste Geschichte, weitere bekannte Cloud-Infrastrukturen für Data Lakes sind ADLS auf Azure und Google Cloud Storage.
Laut Definition speichern Data Lakes Daten in ihrer Rohform – in den traditionellen Strukturen tauchen sie in irgendeiner Weise verändert oder selektiert auf, was sie für die Suche besser erschließt. Herein- und herausgeholt werden die Daten durch einfache Befehle, meistens über sogenannte RESTful-APIs. Das Wahllose des Data-Lake-Inhalts bringt allerdings auch Nachteile mit sich. Von Beratungs- und Marktforschungsunternehmen ist immer wieder zu hören, ein großer Prozentsatz der Data Lakes erfülle die in sie gesetzten universellen Erwartungen nicht.
SQL-Investitionen versus Data-Lakes
Denn unglückseligerweise kommen die Daten aus dem Lake nicht ohne Weiteres in einer Form heraus, in der sie eine geschäftsrelevante Frage gezielt beantworten. Um das zu bewerkstelligen, braucht es erhebliches Wissen und Verständnis der Technologie. Und das haben in den meisten Unternehmen eben nur wenige. Thomas Niewel, Technical Sales Director DACH bei Denodo, einem Spezialisten für Datenvirtualisierung auf der OOP-Konferenz im Januar in München: »Viele Data Lakes werden hauptsächlich von Data Analysts verwendet«.
Die Spezialisten, die sich mit der Aufbewahrung und Erschließung der von Unternehmen gehorteten Daten befassen, haben sich allerdings jahrzehntelang auf SQL eingeschossen. Viele Euros sind in SQL-Kurse, SQL-fähige Tools und SQL-Aufsätze auf SQL-fähige relationale Datenbanken geflossen. Keiner will diese Investitionen so ohne Weiteres aufgeben.
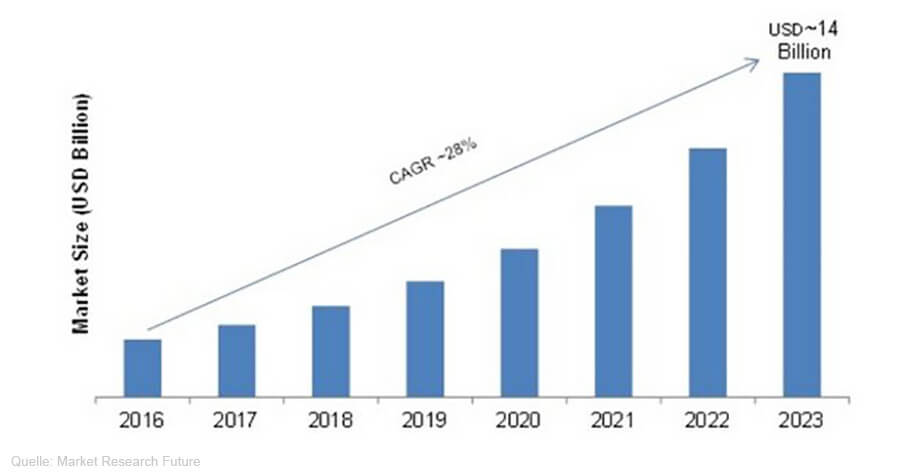 Die Marktentwicklung bei Data-Lakes, wie sie Market Research Future prognostiziert (Bild: Market Research Future).Das Wachstum des Data-Lake-Markts ficht das freilich vorläufig nicht an. Laut einer aktuellen Untersuchung von Market Research Future soll sich dessen Volumen in den kommenden Jahren bis 2023 im Schnitt um jährlich 28 Prozent erhöhen. Am stärksten wachsen Cloud-Services. Markets and Markets kommt zu ähnlichen Schlüssen, hier soll der Markt bei derselben Wachstumsrate von 2,5 Milliarden Dollar 2016 auf 8,81 Milliarden Dollar 2021 zulegen. Mordo Intelligence beziffert die Wachstumsrate wenig abweichend auf 27,3 Prozent. Zu Europa gibt es keine separaten Zahlen.
Die Marktentwicklung bei Data-Lakes, wie sie Market Research Future prognostiziert (Bild: Market Research Future).Das Wachstum des Data-Lake-Markts ficht das freilich vorläufig nicht an. Laut einer aktuellen Untersuchung von Market Research Future soll sich dessen Volumen in den kommenden Jahren bis 2023 im Schnitt um jährlich 28 Prozent erhöhen. Am stärksten wachsen Cloud-Services. Markets and Markets kommt zu ähnlichen Schlüssen, hier soll der Markt bei derselben Wachstumsrate von 2,5 Milliarden Dollar 2016 auf 8,81 Milliarden Dollar 2021 zulegen. Mordo Intelligence beziffert die Wachstumsrate wenig abweichend auf 27,3 Prozent. Zu Europa gibt es keine separaten Zahlen.
Lösungsweg Integration
Das Geheimnis des Erfolgs scheint Integration zu heißen: Data-Warehouse, Data-Mart, Data Lake und was es in Zukunft vielleicht sonst gibt fristen nicht mehr ein getrenntes oder alternatives Dasein. Vielmehr werden sie integriert oder verbunden. So weiß TDWI durch eigene Untersuchungen, dass schon ein Viertel der Data Lakes heute eine oder mehrere relationale Datenbanken enthalten.
Data-Warehouses und Data Lakes werden munter ineinander geschachtelt, hinter- oder voreinander gehängt oder durch spezielle Kanäle miteinander verbunden, wie es etwa Hortonworks vorschlägt. Den Zugriff auf alles kann, wie schon einige Jahre zuvor bei der Storage-Hardware angestrebt, eine Virtualisierungsschicht ermöglichen, diesmal speziell für die Daten. Anbieter solcher Daten-Virtualisierungslösungen gibt es viele. Um nur einige Namen zu nennen: Red Hat bietet Derartiges unter dem JBoss-Label an. Auch Cisco, VMware, Informatica haben solche Werkzeuge in ihren Portfolien.
Dazu kommen Neulinge wie etwa Snowflake, das SQL-Daten in die Cloud bringt, oder crate.io, das mit einem Cloud-Service Streaming-Daten mit anderen Daten integriert und übergreifend mittels SQL analysierbar macht. Attunity, ebenfalls auf der OOP-Konferenz präsent, peppt unter anderem Data Warehouses durch Hadoop, eine der Grundtechnologien von Data-Lakes, auf.
Datenvirtualisierung, bei der ein Data Lake nur eine von vielen Datenaufbewahrungsorten ist, hat übrigens neben Transparenz und Suchbarkeit auch für Nicht-Analytiker noch andere Vorteile. Dann zum Beispiel, wenn Firmen hinzugekauft werden, die ihre eigenen Datenquellen mitbringen. Die Integration der unterschiedlichen Datenwelten gehörte bislang zu den Alpträumen eines jeden Mergers. Die Herausforderung lässt sich zumindest teilweise abmildern, sofern Datenvirtualisierungs-Werkzeuge bereitstehen.
Heißt die Zukunft Data Hub?
Eine andere hochaktuelle Möglichkeit, unterschiedlichen Daten- und Storage-Silos zusammen zu bringen, sind Data-Hubs. Sie integrieren Daten aus allen genannten Bereichen, re-indexieren sie und machen sie suchbar (im Gegensatz zum Data-Lake). Sie können aber, wie gesagt, alle möglichen Arten von Daten speichern.
Beispielsweise bietet Pure Storage eine Data-Hub-Architektur an, die auf Flashblade-Basis realisiert werden soll. Mit Veritas hat man hier bereits einen Backup-Anbieter als Partner gewonnen.
Ein weiterer Anbieter einer solchen Integrationsinfrastruktur ist Mark Logic. Das Unternehmen will in unterschiedlichen Speicher-Silos, darunter auch Data-Lakes, vorgehaltene Daten in einer Cloud-Plattform integrieren, speichern und der Suche zugänglich machen. Zudem sollen die Daten angereichert werden. Mark Logic spricht hier von einer Multi-Modell-Datenintegration. Dabei werden die ACID-Regeln zur Konsistenz von Dokumenten und Daten eingehalten. Das Ganze wird als Cloud-Service angeboten.
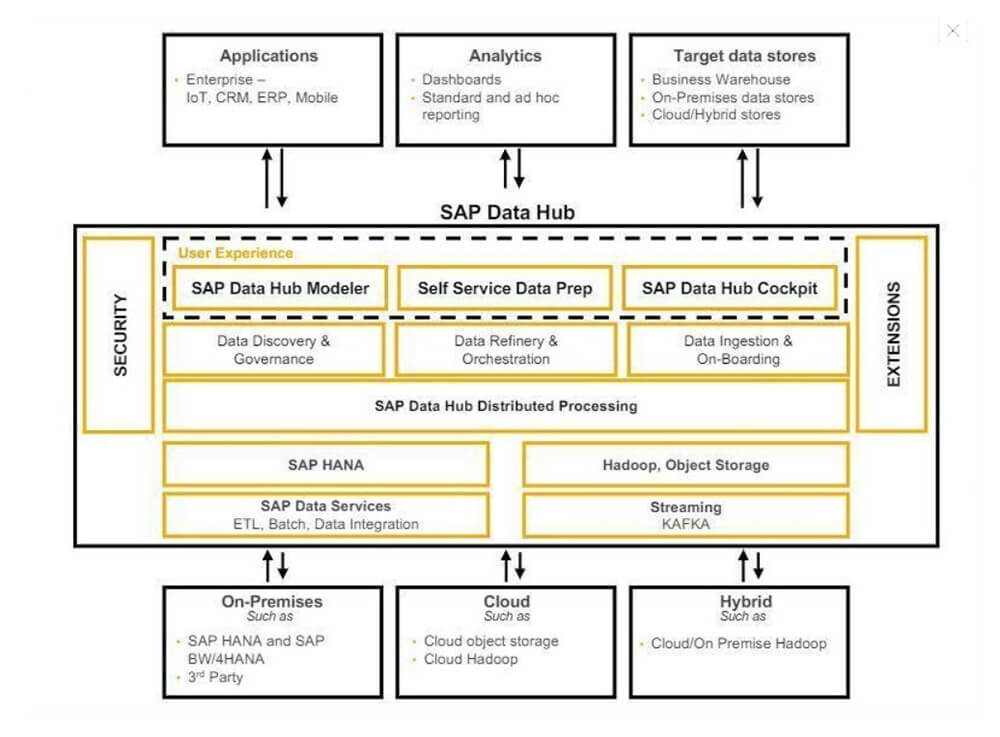 SAPs Data-Hub-Architektur (Bild: SAP)Auch SAP bietet ein als Data Hub bezeichnetes Integrationswerkzeug an. Dabei werden Cloud-Object-Stores unter Hadoop, Daten aus SAP, SAP HANA und anderen Quellen miteinander integriert. Anschließend werden sie mittels diverser aufgelagerter Softwareschichten vorverarbeitet. Schließlich stehen sie den unterschiedlichen Anwendungen wie Datenbanken und Analytik zur Verfügung.
SAPs Data-Hub-Architektur (Bild: SAP)Auch SAP bietet ein als Data Hub bezeichnetes Integrationswerkzeug an. Dabei werden Cloud-Object-Stores unter Hadoop, Daten aus SAP, SAP HANA und anderen Quellen miteinander integriert. Anschließend werden sie mittels diverser aufgelagerter Softwareschichten vorverarbeitet. Schließlich stehen sie den unterschiedlichen Anwendungen wie Datenbanken und Analytik zur Verfügung.
Crate.io, Anbieter eines reinen Cloud-Services, legt zwischen auf SQL aufgelagerte Tools und gemischte Datenquellen eine Art Middleware. Sie macht sämtliche Datenquellen über SQL suchbar und schützt damit die SQL-Investitionen der Firmen. Gleichzeitig können alle bisherigen Investitionen in neue und alte Daten- und Speichertechnologie als nunmehr vereinheitlichte Erkenntnisquelle weiter genutzt werden.
Data Lakes: Zukunft weiter ungeklärt
Welche Methoden und Technologien sich am Ende durchsetzen, um aus dem Datenchaos, das in vielen Unternehmen herrscht, Ordnung zu schaffen, ist noch längst nicht entschieden. Vielmehr entsteht hier ständig Neues. Der Data Lake allein wird es aber entgegen allen anfangs wohl recht überzogenen Hoffnungen kaum sein.