
Objektspeicher im Rechenzentrum
 Objektspeicher helfen, stark wachsende Datenmengen beherrschbar zu halten, ohne dass Verwaltung und Kosten aus dem Ruder laufen. Besonders für Backup, Archiv und große Datenablagen für Auswertungen sind sie oft die pragmatische Wahl. Wichtig sind dabei Unterschiede zu File- und Block-Speicher sowie Kriterien wie Schutz und Datensouveränität.
Objektspeicher helfen, stark wachsende Datenmengen beherrschbar zu halten, ohne dass Verwaltung und Kosten aus dem Ruder laufen. Besonders für Backup, Archiv und große Datenablagen für Auswertungen sind sie oft die pragmatische Wahl. Wichtig sind dabei Unterschiede zu File- und Block-Speicher sowie Kriterien wie Schutz und Datensouveränität.
Objektspeicher sind so etwas wie ein digitales Lager für Daten. Alles, was abgelegt wird, kommt als einzelnes »Paket« hinein. Dieses Paket enthält die Daten selbst, zum Beispiel ein Backup, ein Video oder einen Log-Ausschnitt. Dazu kommt ein »Etikett« mit Zusatzinfos, etwa Projekt, Aufbewahrungsfrist oder Schutzklasse. Und es gibt eine eindeutige Adresse, mit der sich das Paket später wiederfinden lässt. Genau dieses Trio macht den Kern aus: Daten, Etikett, Adresse.
Wichtig ist dabei, wie man an die Daten herankommt. Objektspeicher werden meist nicht wie ein klassisches Laufwerk mit Ordnern und Unterordnern genutzt, sondern über eine Schnittstelle, also über Anfragen übers Netz. Anwendungen oder Tools sagen sinngemäß: »Gib mir Objekt X aus Bucket Y« oder »Speichere dieses Objekt unter Schlüssel Z«. Der Vorteil davon ist, dass sich sehr große Datenmengen gut verteilen und verwalten lassen, ohne dass ein komplexer Verzeichnisbaum irgendwann zum Bremsklotz wird.
Von den frühen Archiv-Systemen zum S3-Standard
Die Idee, Daten »objektartig« mit Identität und Metadaten abzulegen, ist älter als der heutige Cloud-Hype. In der Praxis wurden frühe Ansätze Anfang der 2000er-Jahre sichtbar, zum Beispiel mit EMC Centera (2002) als Content-Addressed-Storage-System für Archivierung und Compliance.
Parallel dazu wurde Object-based-Storage auch standardisiert. Das ANSI INCITS T10 Gremium ratifizierte 2004 einen Object-based-Storage-Device-Befehlssatz (OSD) als SCSI-Erweiterung.
Den großen Durchbruch in der Breite brachte dann die Cloud. Amazon Web Services (AWS) Amazon S3 wurde im März 2006 angekündigt und kurz darauf als Dienst gestartet. S3 hat Object-Storage für viele Teams zum Default gemacht, weil die Nutzung per Web-API und die nahezu unbegrenzte Skalierung plötzlich »einfach bestellbar« waren.
Was Objektspeicher anders machen als File- und Block-Speicher
- File-Storage organisiert Daten als Dateien in Ordnern. Das ist für Menschen und viele klassische Anwendungen bequem, weil sich alles wie ein normaler Dateibaum anfühlt.
- Block-Storage arbeitet darunter eine Ebene tiefer. Er liefert rohe Speicherblöcke, aus denen erst ein Dateisystem oder eine Datenbank etwas Nutzbares macht. Das ist typischerweise die Welt von Datenbanken, VM-Volumes und transaktionslastigen Workloads.
- Object-Storage speichert dagegen jedes Objekt als »Einheit« inklusive Metadaten und eindeutiger Kennung, meist in einem flachen Namensraum innerhalb eines Buckets. »Ordner« sind oft nur Teil des Objekt-Namens, also eher Etikett als echte Verzeichnisstruktur.
Der praktische Unterschied ist damit nicht nur »andere Verpackung«, sondern auch ein anderes Zugriffsmodell: Object-Storage wird über APIs angesprochen und ist darauf ausgelegt, viele Objekte sehr groß zu skalieren, statt ein Dateisystem mit immer mehr Verzeichnissen und sehr vielen kleinen Datei-Operationen zu quälen.
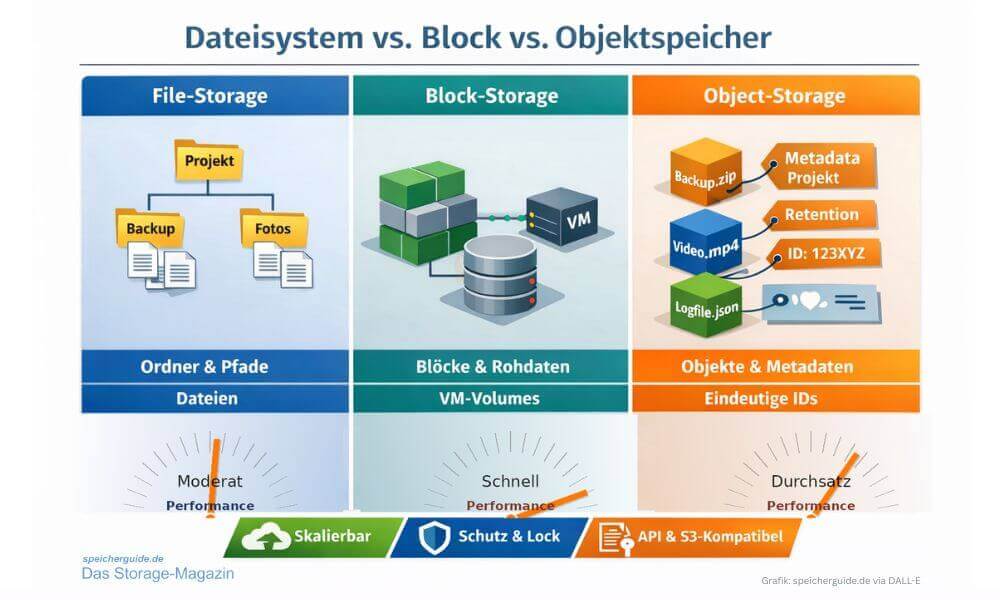 Vergleich von File-, Block- und Object-Storage: Block-Storage liefert meist die höchste IOPS-Performance, Objektspeicher punkten mit hohem Durchsatz und Skalierung, File-Storage liegt typischerweise dazwischen. (Grafik: speicherguide.de via DALL-E)
Vergleich von File-, Block- und Object-Storage: Block-Storage liefert meist die höchste IOPS-Performance, Objektspeicher punkten mit hohem Durchsatz und Skalierung, File-Storage liegt typischerweise dazwischen. (Grafik: speicherguide.de via DALL-E)
Konkrete Vorteile von Objektspeicher
1) Skalierung für sehr große Datenmengen
Objektspeicher sind für Wachstum gebaut. Kapazität wird in Scale-out-Architekturen typischerweise durch zusätzliche Nodes erweitert. Für Umgebungen mit stark wachsendem Anteil unstrukturierter Daten ist das oft der wichtigste Treiber.
2) Metadaten als Steuerungs- und Governance-Werkzeug
Metadaten sind nicht nur »nice to have«. Sie ermöglichen Policies für Aufbewahrung, Tiering, Schutz, Suche und automatisierte Lebenszyklen. Das ist ein Unterschied zu File-Storage, bei dem Metadaten im Alltag oft auf »Name, Datum, Rechte« zusammenschrumpfen.
3) Gute Basis für Archiv, Backup-Ziele und Data-Lakes
Wenn Daten selten gelesen werden, aber lange sicher liegen müssen, spielt Object-Storage seine Stärken aus. Viele S3-basierte Architekturen zielen genau darauf, große Mengen langlebiger Daten per API verfügbar zu halten, statt sie in Spezial-Silos zu parken.
4) Zugriff über standardisierte Schnittstellen
S3 ist de facto das verbreitetste API-Modell. Das ist für IT-Manager relevant, weil es Integrationsrisiken reduziert, wenn Backup-Software, Analytics-Tools und Eigenentwicklungen dieselbe Schnittstelle sprechen.
5) »Schutz per Design« ist möglich, aber nicht automatisch
Viele Object-Storage-Plattformen setzen auf Konzepte wie Unveränderbarkeit und Versionierung. Das kann für Ransomware-Resilienz und Compliance ein starkes Argument sein. Entscheidend bleibt jedoch, wie IAM, Aufbewahrung und Admin-Rechte umgesetzt sind.
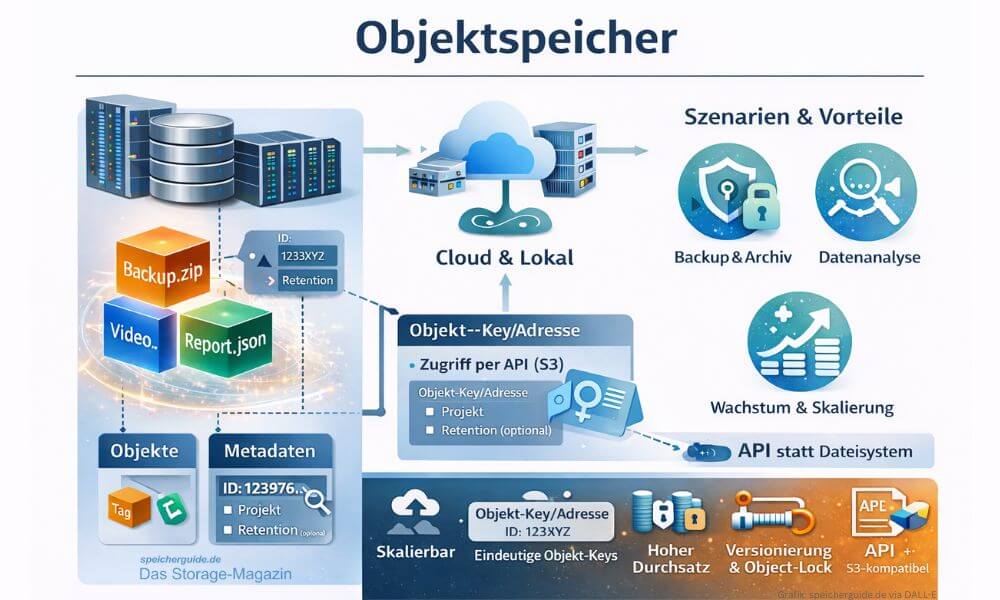 Objektspeicher legen Daten als Objekte mit Metadaten und Objekt-Key ab und werden meist per API, häufig S3-kompatibel, genutzt. Damit eignen sie sich besonders für skalierbare Backup- und Archiv-Repositories sowie für Analyse- und Data-Lake-Szenarien. (Grafik: speicherguide.de via DALL-E)
Objektspeicher legen Daten als Objekte mit Metadaten und Objekt-Key ab und werden meist per API, häufig S3-kompatibel, genutzt. Damit eignen sie sich besonders für skalierbare Backup- und Archiv-Repositories sowie für Analyse- und Data-Lake-Szenarien. (Grafik: speicherguide.de via DALL-E)
API-Semantik: Object-API statt Dateisystem
Objektspeicher werden in der Regel über eine Object-API angesprochen, meist S3-kompatibel. Das klingt nach Detail, ist aber die Grundlage für alles Weitere. Es gibt kein klassisches »Laufwerk«, das Betriebssystem und Anwendungen wie ein lokales Dateisystem behandeln. Stattdessen kommen Operationen wie »PUT«, »GET«, »LIST« und »DELETE« zum Einsatz, oft ergänzt um Multipart-Uploads für große Objekte.
Das hat praktische Folgen. Objektspeicher sind stark bei großen, sequentiellen Transfers und bei parallelen Zugriffen vieler Clients. Sie sind meist weniger glücklich bei sehr vielen kleinen Objekten und bei Workloads, die ständig Metadaten abfragen oder viele kleine Datei-Operationen erwarten. Wichtig ist außerdem, ob und wie gut Funktionen wie Versionierung, Tagging, Object-Lock, Events und Lifecycle-Policies unterstützt werden, denn genau daran hängen Backup-Schutz, Archivierung und Automatisierung.
Konsistenz: Wann ist ein Objekt »wirklich da«
Bei Filesystemen ist das mentale Modell oft einfach. Datei geschrieben, Datei vorhanden, alle sehen sie sofort. Bei Objektspeichern hängt es vom System ab, wie Schreib- und Leseoperationen konsistent umgesetzt sind. Moderne Plattformen zielen häufig auf starke Konsistenz, aber es lohnt sich, die Details zu prüfen, gerade bei verteilten Setups über mehrere Standorte.
Für viele typische Einsätze wie Backup-Repository oder Archiv ist das weniger kritisch, solange die Backup-Software korrekt mit der Object-API arbeitet. Für Anwendungen, die direkt auf dem Objektspeicher Daten austauschen und dabei auf »sofortige Sichtbarkeit« angewiesen sind, kann das dagegen entscheidend sein. Auch LIST-Operationen und Metadaten-Updates können je nach Implementierung anders wirken als erwartet.
Erasure-Coding: Schutz ohne Kopien, aber mit Mathematik
Objektspeicher erreichen Haltbarkeit typischerweise über Replikation oder Erasure-Coding. Replikation ist leicht zu verstehen, weil mehrere vollständige Kopien vorliegen. Erasure-Coding zerlegt Daten in Fragmente plus Parität und verteilt diese über Nodes oder Standorte. Das spart Kapazität gegenüber reiner Mehrfachkopie, kann aber bei Wiederherstellung, Rebuilds und bei bestimmten Zugriffsmustern mehr Netzwerk und mehr Rechenleistung verursachen.
Für die Praxis zählen weniger theoretische Verfügbarkeitswerte als die konkreten Rahmenbedingungen. Wie groß sind typische Objekte. Wie lange dauern Rebuilds nach Node-Ausfällen. Welche Netzwerktopologie liegt darunter. Wie wirkt sich das auf Performance während eines Degradationszustands aus. Ein Objektspeicher, der im Fehlerfall zwar »hält«, aber im Tagesbetrieb dann in Zeitlupe läuft, ist in der Realität schwer vermittelbar.
Netzwerk: Ohne sauberes Design wird es teuer und langsam
Objektspeicher sind netzwerkzentriert. Der Datenpfad läuft praktisch immer über IP, häufig über TLS. Damit werden Bandbreite, Latenz, Paketgrößen, Load-Balancing, interne East-West-Last im Cluster und die Anbindung der Clients zu echten Stellschrauben. Das gilt besonders, wenn viele parallele Streams laufen, etwa bei Backup-Fenstern oder beim Ingest großer Datenmengen.
Wichtige Punkte sind die Platzierung von Gateways oder Endpunkten, die Skalierung der Frontends, die Verteilung der Metadaten-Last und die Frage, ob mehrere Standorte im Spiel sind. Sobald Geo-Replikation oder Standort-übergreifendes Erasure-Coding eingesetzt wird, sind WAN-Bandbreite und Stabilität nicht mehr »nice to have«, sondern Grundlage für Planbarkeit.
Kostenmodelle: Nicht nur TByte zählen
Kostenseitig ist Objektspeicher oft attraktiv, wenn viel Volumen bei moderaten Zugriffsraten gespeichert wird. In der Cloud wird das Modell schnell mehrdimensional. Kapazität ist nur ein Teil, dazu kommen API-Requests, Abrufkosten je nach Storage-Klasse, Datenabfluss und manchmal auch Mindesthaltedauern. Ein Data-Lake, der ständig Daten hin und her schiebt, kann so teurer werden als erwartet, obwohl der Preis pro TByte gut aussieht.
On-Prem verschiebt sich der Fokus. Dort zählen Hardware, Betrieb, Energie, Wartung, Lifecycle-Management und die Frage, wie effizient Schutzverfahren die Rohkapazität nutzen. Zusätzlich sollte der Aufwand für Monitoring, Mandantenfähigkeit, Audit und Schlüsselmanagement eingeplant werden, weil diese Funktionen in Object-Storage-Umgebungen zentral sind und nicht als Nebenprodukt eines Filesystems anfallen.
Kurz gesagt: Die fünf Prüfsteine
Ein Objektspeicher-Projekt steht und fällt meistens an fünf Punkten:
- API-Funktionsumfang und Kompatibilität, inklusive der Schutzfunktionen wie Versionierung und Object-Lock.
- Konsistenz und Semantik, damit Anwendungen und Tools nicht gegen unerwartetes Verhalten laufen.
- Das Schutzverfahren, also Replikation oder Erasure-Coding, samt Rebuild-Verhalten.
- Netzwerkdesign und Endpunkt-Skalierung.
- Ein realistisches Kostenmodell, das neben Kapazität auch Zugriff, Datenbewegung und Betrieb abbildet.
Marktplayer: Object-Storage nicht nur eine Logo-Frage
Beim Object-Storage ist der Markt inzwischen breit. Analysten sprechen von einer deutlich wachsenden Zahl an Anbietern. Das heißt, IT-Abteilungen stehen mittlerweile ein ganzes Ökosystem aus Cloud-Services, Enterprise-Plattformen und Software-defined-Angeboten zur Verfügung.
In der Praxis hilft eine Einteilung in drei Gruppen, weil sich dahinter unterschiedliche Stärken und Betriebsmodelle verbergen:
- Erstens die globalen Hyperscaler. Amazon Web ServicesAmazon S3 bleibt die Referenz, auch weil viele Tools und Produkte »S3-kompatibel« praktisch als Mindestanforderung behandeln. Daneben sind MicrosoftAzure Blob Storage und Google Cloud Storage in vielen Architekturen gesetzt, weil sie eng mit Analytics-, KI- und Plattformdiensten verzahnt sind.
An dieser Stelle kommt aber der Datensouveränitäts-Haken ins Spiel. Selbst wenn Daten in einer EU-Region liegen, können rechtliche und organisatorische Anforderungen weitergehen als reine Datenresidenz. Deshalb lohnt es sich, europäischen Alternativen zumindest einen festen Platz in der Shortlist zu geben, wenn die Governance-Vorgaben eng sind. - Zweitens europäische Cloud-Alternativen, die explizit Object-Storage mit S3-kompatiblem Zugriff anbieten. OVHcloud beschreibt sein Object-Storage als S3-kompatibel und verweist explizit darauf, dass S3-kompatible Tools in der Regel funktionieren. Scaleway dokumentiert Object-Storage ebenfalls als Nutzung mit Amazon-S3-kompatiblen Clients. IONOS positioniert Object Storage als S3-kompatiblen Dienst, inklusive Integrationsnennung für S3-Tools. Mit STACKIT ist ein weiterer deutscher Anbieter dabei, der die S3-Kompatibilität der Schnittstelle explizit herausstellt. Für den DACH-Raum ebenfalls häufig auf Radar ist Hetzner mit S3-kompatiblem Object-Storage.
Und wer Schweiz und EU als Betriebsraum interessant findet, stößt oft auf
Exoscale, das sein Object-Storage als S3-kompatibel beschreibt. Als europäische Option in Enterprise-Kontexten wird außerdem Open Telekom Cloud genannt, deren Release Notes für Object-Lock ausdrücklich S3-Kompatibilität adressieren. - Drittens klassische Enterprise- und RZ-Plattformen für On-Premises und Hybrid. Hier trifft man als Betreiber besonders häufig auf objektfokussierte Systeme oder Unified-Plattformen, die Object-Storage zusätzlich anbieten. Typische Namen in diesem Feld sind Dell Technologies mit ECS und ObjectScale, NetApp mit StorageGRID, IBM mit Cloud Object Storage, Hitachi Vantara mit seiner Content Platform, außerdem Anbieter wie Scality mit RING oder Cloudian mit HyperStore.
In Cloud-native-Umgebungen spielen zusätzlich Kubernetes-nahe Angebote wie
MinIO eine Rolle, oft als S3-kompatibler Baustein für Data-Lake- und KI-Pipelines. Dass diese Herstellergruppe in Analystenvergleichen prominent vertreten ist, zeigt auch die vendor-lastige Berichterstattung rund um die GigaOm-Radar-Auswertung.
Fast alle Speicheranbieter haben heute irgendeine Form von Object-Storage-Angebot. Der Haken ist das Wort »irgendeine«. Viele haben etwas, das sich im Datenblatt nach Object-Storage liest, aber die Ausprägung unterscheidet sich stark. Im Feld sieht man drei Varianten: Ein echtes, nativ verteiltes Object-Storage-System. Eine Scale-out- oder Unified-Plattform, die Datei und Objekt parallel anbietet. Oder ein S3-Gateway, das Object-Zugriffe vor ein anderes Storage-Backend setzt. Das ist funktional manchmal ausreichend, ist aber nicht automatisch gleichwertig, etwa bei S3-Funktionsabdeckung, Mandantenfähigkeit, Object-Lock-Verhalten, Performance bei kleinen Objekten und beim Verhalten in Degradations- und Rebuild-Situationen.
Merkliste: Souveränitäts-Check für Object-Storage-Plattformen
RZ-Betreiber sollten beim Vergleich von Hyperscalern, europäischen Cloud-Angeboten und On-Premises-Objektspeichern mit Blick auf Datensouveränität vor allem diese Punkte abklopfen:
- Wo liegen die Daten physisch und wo laufen Control-Plane, Support-Zugriffe und Logdaten, also nicht nur »Data Residency«, sondern die komplette Betriebs- und Verwaltungskette.
- Welche Rechts- und Vertragsbasis gilt, inklusive Auftragsverarbeitung, Unterauftragnehmern und klaren Regelungen zu Behördenanfragen sowie Transparenzberichten.
- Wie wird Mandantenfähigkeit umgesetzt, ob es echte Tenant-Isolation gibt, und wie granular IAM, Policies und Auditing sind.
- Wer verwaltet Schlüssel und Identitäten, ob BYOK, HYOK oder kundeneigene KMS-Hardware möglich ist, und ob das Key-Management technisch und organisatorisch vom Provider entkoppelt werden kann.
- Ob Immutability wirklich belastbar ist, also Object-Lock, Aufbewahrungsfristen und »Legal Hold« inklusive Schutz gegen Admin-Fehlbedienung und Rollentrennung.
- Wie Datenportabilität aussieht, also S3-Funktionsabdeckung, Migrations-Tools, Performance beim Export und ein realistisches Exit-Szenario ohne Überraschungen durch Egress, Retrieval oder API-Request-Kosten.
- Wie sich Datenklassifizierung und Lifecycle-Policies abbilden lassen, damit Aufbewahrung, Löschung und Tiering nicht zum manuellen Dauerjob werden.
Und zuletzt ganz profan, aber oft entscheidend: Welche Betriebsmodelle der Anbieter ermöglicht, etwa dedizierte EU-Regionen, souveräne Cloud-Optionen, lokale Betriebsführung oder eine echte Hybrid-Architektur, bei der sensibelste Daten On-Premises bleiben und nur definierte Teilmengen in die Cloud wandern, ohne dass am Ende doch wieder alles an einem zentralen US-Konto hängt.
Fazit: Objektspeicher als Plattformentscheidung
Objektspeicher sind heute weniger ein exotisches Spezialthema als eine pragmatische Antwort auf wachsende Mengen unstrukturierter Daten. Sie spielen ihre Stärken aus, wenn Kapazität und Datenhaltbarkeit wichtiger sind als minimale Latenz, und wenn Prozesse wie Aufbewahrung, Schutz und Datenbewegung automatisiert werden sollen. Damit eignen sie sich besonders als Basis für Backup- und Archiv-Ziele, als Repository für Plattformdienste und als Fundament für Data-Lake-Ansätze.
Entscheidend ist, Objektspeicher nicht nur als »S3-Bucket« zu betrachten, sondern als Plattformentscheidung. API-Verhalten, Schutzmechanismen, Netzwerkdesign und Betriebsmodell bestimmen, ob das Ergebnis robust und beherrschbar wird. Wer zusätzlich Datensouveränität sauber abklopft, hat am Ende nicht nur günstige TByte, sondern ein System, das im Audit und im Krisenfall genauso überzeugend ist wie im Datenblatt.