
Secondary-Storage entscheidend für Erfolg von Speicherkonzepten
 Unstrukturierte Daten dominieren die Speicherlandschaft – und treiben Kosten, Risiko und Komplexität. IDC prognostiziert bis 2028 nahezu eine Verdreifachung der weltweiten Datenerzeugung. Wer Secondary-Storage nur als Ablage versteht, verschenkt Potenzial. Entscheidend sind Tiering, Governance und Cyber-Resilienz.
Unstrukturierte Daten dominieren die Speicherlandschaft – und treiben Kosten, Risiko und Komplexität. IDC prognostiziert bis 2028 nahezu eine Verdreifachung der weltweiten Datenerzeugung. Wer Secondary-Storage nur als Ablage versteht, verschenkt Potenzial. Entscheidend sind Tiering, Governance und Cyber-Resilienz.
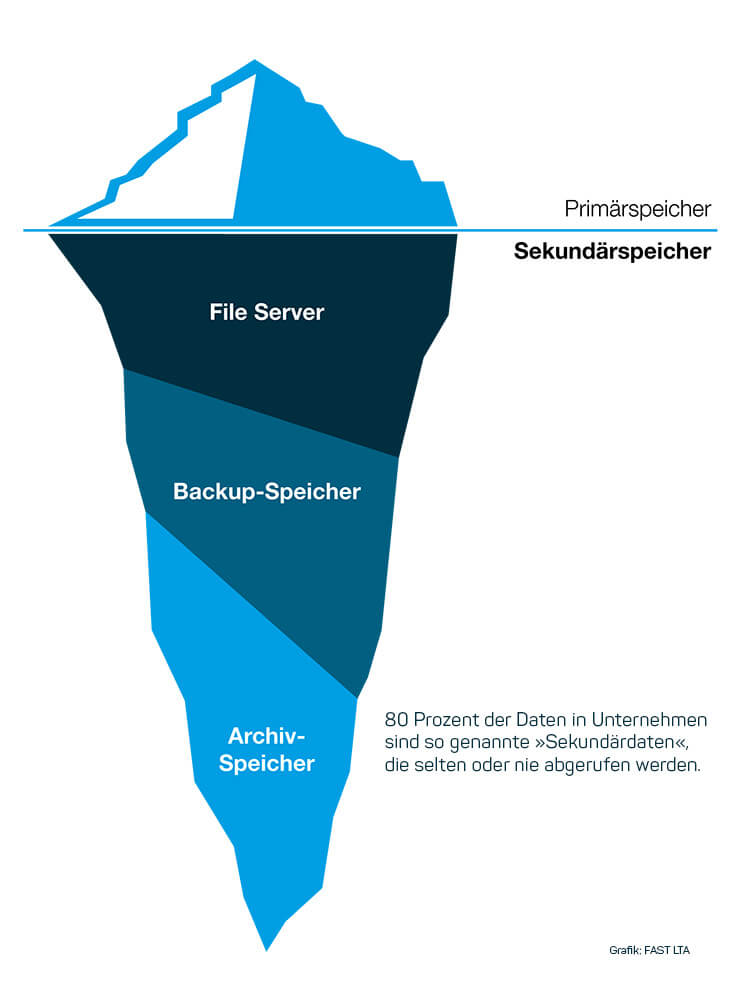 Der Großteil der erzeugten Daten sind Sekundärdaten, die selten benötigt werden (Grafik: Fast LTA).
Der Großteil der erzeugten Daten sind Sekundärdaten, die selten benötigt werden (Grafik: Fast LTA).
Die Unterteilung in »Primärdaten« und »Sekundärdaten« stammt aus einer Zeit, in der die großen, monolithischen Systeme als Heiliger Gral der Firmen-IT das Denken bestimmten. Ausgehend vom ERP-System wurde darum herum das gesamte Unternehmen organisiert. Sie dienten zum Betrieb und der Steuerung und erfassten alle wichtigen Bereiche. Was nicht in den Datenbanken dieser Systeme liegt, kann gar nicht wichtig sein. So die unterschwellige Annahme.
Diese Annahme war damals schon falsch. Die Bedeutung der unstrukturierten Daten außerhalb der Datenbanken der großen Software-Suiten hat seitdem aber noch stark zugenommen: Durch Richtlinien zu Aufbewahrung und Archivierung sowie den betriebswirtschaftlichen Wunsch und die technischen Möglichkeiten, einmal »woher auch immer« gesammelte Daten später auszuwerten, um daraus Erkenntnisse zu gewinnen mit denen sich geschäftliche Entscheidungen fällen und begründen lassen.
Immer mehr Sekundärdaten in Unternehmen
Das Hauptproblem ist, dass die ungeliebten und verachteten Sekundärdaten wesentlich mehr Speicherplatz beanspruchen als die sorgsam gepflegten und gehegten Primärdaten. Ein weiteres Problem ist, dass der Wert der Sekundärdaten oft lange unklar bleibt. Einige von ihnen gewinnen erst nach einem längeren Zeitraum an Wert. Sie ganz zur Seite zu legen ist aber nicht möglich. Schließlich sollen sie für Analytics-Tools, Machine-Learning und vor allem Anwendungen im Bereich Künstliche Intelligenz (KI) verfügbar sein.
Die weltweit erzeugte Datenmenge steigt weiter stark an. IDC rechnet damit, dass die globale Datenerzeugung von 132,4 ZByte (2023) auf 393,9 ZByte (2028) wächst. Diese Größenordnung erklärt, warum Sekundärdaten nicht als Randthema behandelt werden können, sondern als eigener Planungs- und Kostenblock im Storage-Konzept.
Entscheidend ist dabei die Unterscheidung zwischen »erzeugt« und »dauerhaft gespeichert«. IDC verweist darauf, dass nur ein Teil der erzeugten Daten langfristig abgelegt wird. Trotzdem wächst die installierte Storage-Basis deutlich. Die Marktforscher erwarten, dass die installierte Kapazität von 9,3 ZByte auf 19,2 ZByte im Zeitraum 2023 bis 2028 steigt. Damit wird Secondary-Storage zu einem eigenen Architekturthema, weil Kapazität nicht mehr nur mitwächst, sondern aktiv verteilt, geschützt und betrieben werden muss.
Wie stark sich die Daten in »Temperaturklassen« aufteilen, zeigt eine IDC-Einschätzung, die Quantum beauftragt hat. Demnach gelten rund 60 Prozent der gespeicherten Daten als kalt, 30 Prozent als warm mit wöchentlichem bis monatlichem Zugriff. Auf nur zehn Prozent wird häufig zugegriffen, also stündlich oder täglich. Praktisch bedeutet das: Für rund 90 Prozent der Daten zählen Kosten pro TByte, Schutzmechanismen und Governance oft mehr als maximale IOPS.
IDC beziffert im selben Kontext das Wachstum der installierten Speichersysteme zwischen 2020 und 2025 mit 30,9 Prozent durchschnittlichem Wachstum und nennt als Größenordnung 5,5 ZByte. Zusätzlich wird für Public-Cloud-Dienste ein jährliches Wachstum von bis zu 4,2 ZByte genannt. Das unterstreicht, dass Secondary-Storage in vielen Umgebungen als Mix aus On-Premises-Tiers, Cloud-Tiers und Archiv-Tiers gedacht werden muss, inklusive klarer Regeln, welche Daten wann wohin wandern und wie lange sie dort bleiben.
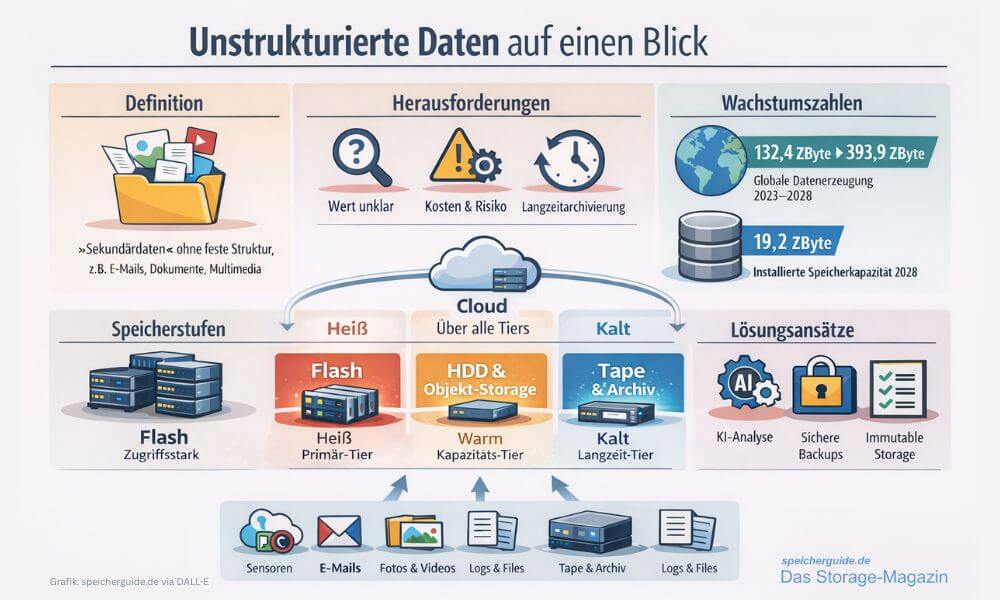 Unstrukturierte Daten dominieren das Speicherwachstum und erfordern differenzierte Tiers, klare Governance sowie resiliente Secondary-Storage-Konzepte. (Grafik: speicherguide.de via DALL-E)
Unstrukturierte Daten dominieren das Speicherwachstum und erfordern differenzierte Tiers, klare Governance sowie resiliente Secondary-Storage-Konzepte. (Grafik: speicherguide.de via DALL-E)
Medienmix, Marktvolumen und Tape als 2026-Anker
Der Medienmix im Rechenzentrum bleibt heterogen, weil Workloads unterschiedliche Anforderungen an Latenz, Durchsatz, Parallelität und Kosten pro TByte stellen. IDC erwartet, dass Festplatten in Hyperscale- und Cloud-Rechenzentren bis 2028 weiterhin nahezu 80 Prozent der genutzten Storage-Kapazität abdecken. Damit bleibt Kapazitäts-Storage auf HDD-Basis ein tragender Baustein für Secondary-Storage, insbesondere für Daten-Tiering, Backup-Repositorys und große Objekt-Storage-Pools.
Auch die Marktzahlen sprechen dafür, Secondary-Storage als strategische Komponente zu behandeln. Omdia prognostiziert, dass der Umsatz mit Datacenter-Storage bis 2028 auf 103 Milliarden US-Dollar steigt. Für 2023 nennt Omdia 53 Milliarden US-Dollar und beschreibt den folgenden Zeitraum als Erholung mit Wachstum und höheren Durchschnittspreisen. Das passt zu einem Markt, in dem weniger einzelne Systeme im Vordergrund stehen, sondern Gesamtkonzepte aus Plattform, Schutzfunktionen und Betriebsmodell.
Für Archiv- und Offline-Tiers liefert Tape einen konkreten 2026-Anker. Das LTO-Programm meldet für 2024 176,5 EByte ausgelieferte Bandkapazität, ausdrücklich als komprimierte Kapazitätsangabe, und nennt 15,4 Prozent Wachstum gegenüber 2023. Zusätzlich kündigt Fujifilm LTO-10-Cartridges mit 40 TByte nativ und 100 TByte komprimiert an, mit Auslieferungsbeginn Januar 2026. Damit bleibt Tape als Offline-Speicherklasse für Langzeitaufbewahrung und Cyber-Resilienz in vielen Speicherkonzepten ein realistischer Baustein.
Datenmanagement statt Speichermanagement
Datenmanagement entscheidet heute häufiger über Kosten, Risiko und Nutzwert als die reine Auswahl eines Speichermediums. Der Grund ist banal und unangenehm zugleich. In Hybrid-IT und verteilten Speicherklassen entstehen Datenbestände, die ohne klare Regeln schnell unübersichtlich werden. Daten liegen mehrfach, sind unzureichend klassifiziert oder haben keine sauberen Aufbewahrungs- und Löschfristen. Genau dort kippt Secondary-Storage von »günstigem Kapazitäts-Tier« zu »teurem Dauerparkplatz«. Bits sind geduldig, Budgets eher nicht.
Eine belastbare Zahl für den wirtschaftlichen Effekt liefert Gartner über die Hintertür der Datenqualität. Schlechte Datenqualität kostet Unternehmen im Schnitt mindestens 12,9 Millionen US-Dollar pro Jahr. Das ist zwar keine reine Storage-Kennzahl, hängt in der Praxis aber stark an fehlender Data-Governance, Metadaten-Disziplin und Silos. Wenn nicht klar ist, was Daten sind, wem sie gehören, wie lange sie gebraucht werden und wer darauf zugreifen darf, werden sie vorsorglich behalten, kopiert und überall gespiegelt. Damit steigen Kapazität, Backup-Footprint und Betriebslast gleichzeitig.
Der Druck kommt zusätzlich aus dem Einsatz von KI und Analytics. Gartner erwartet, dass bis 2027 60 Prozent der Organisationen den erwarteten Wert ihrer KI-Use-Cases nicht realisieren, wenn Data-Governance-Frameworks inkohärent bleiben. Das betrifft nicht nur KI-Projekte. Die gleiche Schwäche zeigt sich in Tiering-Strategien, in E-Discovery-Prozessen oder bei der Frage, welche Daten überhaupt in ein Objekt-Storage-Tier oder in ein Archiv dürfen. Ohne Klassifizierung, Ownership und Richtlinien bleibt am Ende nur Bauchgefühl.
Dass Data-Governance und Datenhoheit inzwischen harte Investitionstreiber sind, zeigt auch der Souveränitäts-Trend im Cloud-Umfeld. Gartner prognostiziert für souveräne Cloud-IaaS-Ausgaben 80,4 Milliarden US-Dollar in 2026 und 110,6 Milliarden US-Dollar in 2027. Für Europa wird ein Sprung von fast sieben Milliarden US-Dollar (2025) auf rund 23 Milliarden US-Dollar (2027) ausgewiesen. Übersetzt heißt das: Datenhaltung wird stärker nach Standort, Regulatorik und Risiko bewertet. Damit braucht Secondary-Storage zwingend ein Regelwerk, das Daten automatisiert an die passende Speicherklasse und an den passenden Ort steuert.
Der vierte Hebel ist Security. IBM beziffert die globalen Durchschnittskosten einer Datenpanne im Report 2025 mit 4,4 Millionen US-Dollar. Gleichzeitig verweist IBM auf Governance-Lücken rund um KI und Zugriffskontrollen. Für Secondary-Storage ist das relevant, weil gerade Backup-Repositorys, Archive und Objekt-Storage-Tiers attraktive Angriffsziele sind. Data-Management ist hier die Voraussetzung für technische Kontrollen wie unveränderbare Policys, getrennte Admin-Domänen, konsistente Berechtigungen und nachvollziehbare Retention.
Aktuelle Einordnungen aus der Storage-Praxis gehen in dieselbe Richtung. Für 2026 rücken Governance, Recovery, FinOps und Souveränität als Pflichtprogramm in den Vordergrund, parallel zu steigenden Kosten und möglichen Engpässen bei Kapazitäts-Storage. Das passt zur Kernaussage dieses Abschnitts: Secondary-Storage funktioniert nicht über ein einzelnes Produkt, sondern über ein operatives Datenmodell aus Metadaten, Policys und Automatisierung entlang des Data-Lifecycle-Managements.
Automatisierte Datenverwaltung als Ziel
Um die Datenschätze zu heben, ist es aber unerlässlich, die Inhalte zu kennen. Dabei helfen Metadaten oder noch besser durch Klassifizierungs-Tools angereicherte Metadaten. Als einen Vorteil der Datenverwaltung über Metadaten nennen Experten zum Beispiel die Möglichkeit, Datensätze schon bei der Speicherung mit einem Verfallsdatum zu versehen und so Datenschutzbestimmungen einhalten zu können. Auch der Speicherort sollte sich regelbasiert steuern lassen.
Außerdem sind eine Vielzahl weiterer, regelabhängiger Datenfelder vorstellbar. Die Idee dahinter ist, dass nach einer gewissen Zeit, wenn das Regelwerk rund läuft, sich die Daten automatisiert verwalten. Der Betrieb ist sowohl On-Premises als auch in der Cloud möglich. Einstieg ist üblicherweise die Klärung der Frage, welche Daten überhaupt regelmäßig genutzt werden und welche nicht mehr angefasst werden. Das alles lohnt sich natürlich bei großen Datenmengen eher.
Das größte Problem heute: Firmen verwalten meist den Speicherplatz, aber nicht die Daten. Im Zuge der Administration werden alle Daten auf einem Datenträger gleichwertig behandelt. Sortierung findet meist nur durch unterschiedlich zugewiesene Laufwerke statt. Dadurch liegen dann zum Beispiel alle Daten einer Abteilung auf einem Laufwerk von Verträgen bis zu den Fotos der zwanzig letzten Weihnachtsfeiern.
Daten aus der Cloud nicht vergessen
Cloud-Services entlasten beim Betrieb von Infrastruktur, sie nehmen Unternehmen aber nicht automatisch die Verantwortung für Daten ab. Das gilt besonders bei SaaS-Angeboten. Der Cloud-Anbieter sorgt typischerweise für den stabilen Betrieb der Plattform, die Verfügbarkeit der Services und die physische Sicherheit. Themen wie Identitäten und Berechtigungen, Konfigurationen, Datenklassifizierung, Aufbewahrung und die Wiederherstellbarkeit nach Fehlbedienung oder Angriff bleiben jedoch in der Verantwortung des Nutzers. In der Praxis entsteht genau hier eine Lücke, weil »Verfügbarkeit« nicht gleichbedeutend ist mit »Wiederherstellung nach dem Worst Case«.
Gerade bei Kollaboration und Business-Anwendungen entstehen typische Risiken durch versehentliches Löschen, fehlerhafte Policies, unbemerkte Rechteausweitung oder Ransomware, die sich über synchronisierte Clients und API-Zugriffe bis in Cloud-Daten fortpflanzen kann. Secondary-Storage ist in diesem Kontext nicht nur ein günstiges Kapazitäts-Tier, sondern eine zweite, logisch getrennte Sicherheitslinie. Entscheidend sind ein eigenständiges SaaS-Backup mit klaren Restore-Prozessen, getrennte Administrationsdomänen und idealerweise unveränderbare Kopien, damit der Backup-Bestand nicht zur nächsten Angriffsfläche wird. Retention- und eDiscovery-Funktionen helfen bei Aufbewahrungspflichten, sie ersetzen jedoch kein Backup-Konzept, wenn es um granulare Wiederherstellung, saubere Versionierung und definierte RTO- und RPO-Ziele geht.
Object-Storage und Sekundärdaten
Objekt-Storage hat sich als Secondary-Storage-Tier etabliert, weil er große Datenmengen wirtschaftlich abbilden kann und über Standardschnittstellen, in der Praxis meist S3-kompatibel, breit integrierbar ist. Für Backup-Tiering, Archiv-Tiers, Content-Repositories und Data-Lake-orientierte Workloads ist Objekt-Storage häufig die Speicherklasse, in die Daten »hineinfallen«, sobald sie nicht mehr in ein teures Performance-Tier gehören. Der strategische Vorteil liegt weniger im Medium selbst als im Zusammenspiel aus Metadaten, Policies und Automatisierung. Lifecycle-Regeln steuern, wann Objekte verschoben, aufbewahrt oder gelöscht werden. Zusätzlich lassen sich Unveränderbarkeits- und WORM-Mechanismen über Object-Lock- und Retention-Policies abbilden, was Objekt-Storage als Baustein für Cyber-Resilienz interessant macht.
Die oft pauschal diskutierte »Performance-Frage« ist dabei kein generelles Gegenargument, sondern eine Architekturfrage. Objekt-Storage ist nicht dafür gedacht, klassische Block-Storage-IOPS eins zu eins zu ersetzen. Entscheidend sind Zugriffsmuster, Parallelität, Metadaten-Operationen, Netzwerk und das gewählte Design, etwa Gateway-Ansatz, Caching-Schichten, Erasure-Coding-Profile und die Anbindung über schnelle Netze. Für viele Secondary-Workloads, also Backup-Repositorys, große unstrukturierte Datenbestände und kostensensitive Analyse-Pipelines, zählt vor allem Skalierbarkeit, Automatisierung und die Fähigkeit, Daten sicher und nachvollziehbar zu halten. Genau dort spielt Objekt-Storage seine Stärken aus, ohne dass das Konzept in Richtung »alles nur noch Objekt« überdrehen muss.
Sicherheitskonzepte für Sekundärdaten
Hersteller, Sicherheitsverantwortliche und Branchenbeobachter weisen regelmäßig darauf hin, dass Backups einerseits kein Ersatz für eine strukturierte Sekundärdaten-Ablage sind, andererseits aber auch Sekundärdaten eine belastbare Datensicherung benötigen. In der Praxis kommt dabei häufig Tape-Technologie ins Spiel. Bewährt hat sich ein Ansatz mit mehreren Kopien auf unterschiedlichen Speicherklassen, wobei mindestens eine Kopie physisch oder logisch vom produktiven Betrieb getrennt abgelegt wird, um Manipulation und Verschlüsselung durch Angreifer zu erschweren.
Ein weiteres Argument für Tape sind gesetzliche oder versicherungsrechtliche Vorgaben, die eine sehr langfristige Aufbewahrung von Daten erforderlich machen. Auch bei KI-Projekten kann Tape eine Rolle spielen. Zum einen sind hier oft große Datenmengen beteiligt. Zum anderen sollte die Nachvollziehbarkeit der verwendeten Trainings- und Referenzdaten langfristig gesichert sein, weil Fehler in Modellen oder Datenqualität mitunter erst deutlich später auffallen.
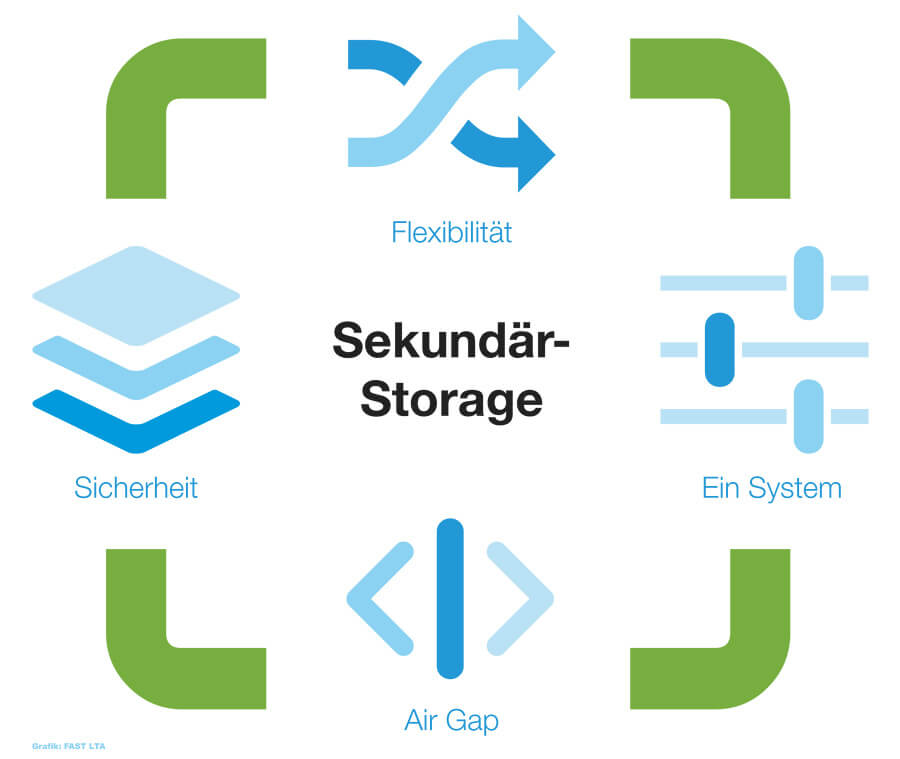 Die physische Trennung von Speichersystemen »Air-Gap« verhindert auch die Ausbreitung von Ransomware (Grafik: Fast LTA).
Die physische Trennung von Speichersystemen »Air-Gap« verhindert auch die Ausbreitung von Ransomware (Grafik: Fast LTA).
Neben Offline-Tiers gehört heute fast immer eine zweite Schutzlinie dazu: unveränderbare Kopien. Ziel ist, dass Backup- und Archivbestände für definierte Zeiträume weder gelöscht noch überschrieben werden können, selbst dann nicht, wenn Angreifer erhöhte Rechte erlangen. Technisch wird das über WORM- und Immutable-Policies umgesetzt, die Retention-Zeiträume erzwingen und Änderungen nachvollziehbar machen. Entscheidend ist weniger das Speichermedium als das Betriebsmodell: getrennte Administrationsdomänen, strikt begrenzte Rechte, ein separater Umgang mit Schlüsseln und Credentials sowie ein unabhängiges Protokollieren reduzieren das Risiko, dass ein Angriff »Backup inklusive« durchläuft. Damit das im Ernstfall nicht nur gut klingt, sollten Restore-Tests als Regelbetrieb etabliert werden, inklusive Recovery einzelner Objekte und kompletter Systemstände.