
HPE ergänzt sich mit Datenanalyseplattform Epic von Bluedata
Die Analyse neu entstehender und bislang ungenutzter Daten soll Unternehmen helfen, veränderte Geschäftsprozesse und -modelle zu kreieren und damit auch erweiterte Wachstumspotentiale aufzutun. Natürlich ist gerade großen IT-Anbietern daran gelegen, dafür ein geeignetes Portfolio aufzubauen. Dazu kaufen sie gern Startups.
Hewlett Packard Enterprise (HPE) hat beispielsweise gegen Jahresende 2018 BlueData übernommen. Das Unternehmen, das mit EPIC eine Plattform für die Big-Data-Analyse, KI (Künstliche Intelligenz) und ML (Machine-Learning) entwickelt hat, konnte bisher einige Dutzend Kunden begeistern. Sie kommen aus Branchen wie Pharma, Finanz- und Versicherungswesen oder Healthcare, die meist in ihren Branchen zu den weltweiten Marktführern gehören. Szenarien, in denen sich Epic als segensreich erweisen könnte, sind die üblichen datenhungrigen Applikationen wie das Finden neuer vielversprechender Moleküle für Medikamente (Drug Discovery) und Therapieansätze, Risikoanalyse und Scoring im Finanz- und Versicherungswesen sowie ähnlich komplexe und gleichzeitig profitträchtige Themen.
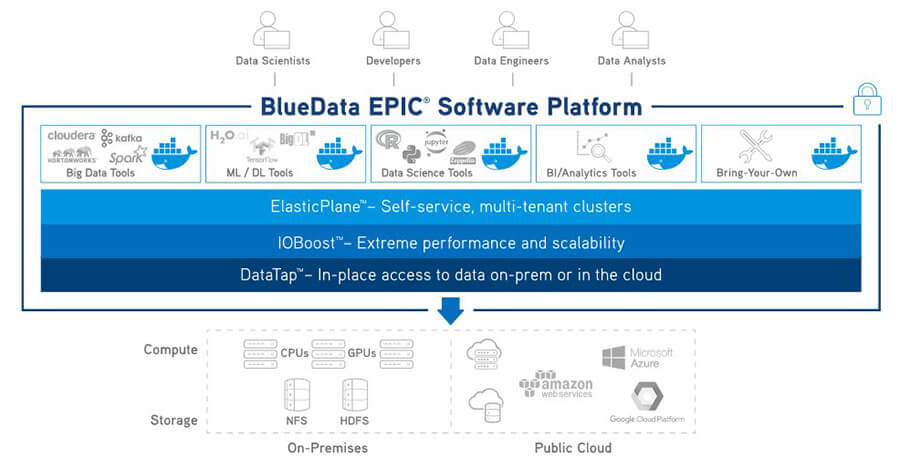 Die Architektur der »EPIC«-Plattform (Grafik: HPE)
Die Architektur der »EPIC«-Plattform (Grafik: HPE)
Das zweite Argument, das HPE wohl zur Übernahme motivierte, sind die Technologien, die hinter der Epic-Plattform stecken. Sie sollen dazu beitragen, dass Datenanalyse aus Sicht der raren Fachleute für dieses Gebiet erheblich einfacher wird.
Bislang müssen sich Dateningenieure, Datenanalysten und Datenwissenschaftler nämlich häufig erst einmal lange damit befassen, geeignete Systeme, Plattformen und Daten-Pipelines aus unterschiedlichen Komponenten selbst zusammenzustricken, ehe sie beginnen können, die erste Analyse zu fahren. Gleichzeitig müssen sie sich gegen den Hang von Fach- oder Compliance-Abteilungen behaupten, Daten zumindest zeitweilig zwecks Analyse auf analytische Systeme, die gern auch in der Cloud liegen, zu verlagern. Oder aber die Geschäftsleitung davon überzeugen, dass es sinnvoll ist, die nötigen, nicht unbeträchtlichen Summen in die Hand zu nehmen, um in entsprechende Plattformen für den Hausgebrauch zu investieren – sei es tatsächlich in Hard- und Software, sei es in die schwer erhältliche Manpower, um aus den durchaus verfügbaren Open-Source-Komponenten ein funktionierendes Ganzes zu machen.
Analytische Umgebung zum Zusammenklicken
Vieles davon soll dank BlueData EPIC mit seinem hohen Automatisierungsgrad erheblich einfacher werden. Wie funktioniert das? Für die Endnutzer in den datenanalytischen Teams wohl am wichtigsten: Die Plattform umfasst ein Selbstbedienungsportal im Web. Es stellt alle nötigen Komponenten bereit, um sich ohne große Kenntnisse über IT-Infrastruktur die gewünschte KI/ML- Umgebung zusammenzuklicken. Neben Epic-Komponenten können in dieses Portal je nach kundenspezifischer Implementierung auch Open-Source-Tools oder andere Werkzeuge bereitgestellt werden. Alles ist so konfiguriert und vorbereitet, dass die benötigten Komponenten mit Point-and-Click zur für die jeweilige Aufgabe benötigten Umgebung verschmelzen.
Auch über REST-Apis und die Nutzerschnittstelle von Epic lassen sich Umgebungen einfach konfigurieren, was aber eher eine Aufgabe für IT-Administratoren bleiben dürfte, während sich die Analytik-Fachleute des Portals bedienen. Ein differenzierbares Rechtesystem im Hintergrund sorgt dafür, dass Tenants, Personen und Rollen nur auf die Komponenten und Daten Zugriff haben, für die sie berechtigt sind. Dabei ist die Lösung hochgradig skalier- und beliebig verteilbar. Tenants sollen sich schnell für bestimmte Niederlassungen, Gruppen, Abteilungen, Anwendungen oder jede beliebige Kombination davon anlegen lassen, und ebenso unkompliziert wieder entfernt werden können.
Die Software-Plattform Epic trennt konsequent auf der logischen Ebene Rechen- von Speicher-Ressourcen und nutzt statt virtueller Maschinen oder proprietärer Hardware ganz schlicht Docker-Container. Diese Container können sich inhouse, bei einem MSP, in einer Public-Cloud der drei Hyperscaler oder sonstwo befinden – auch an allen genannten Orten gleichzeitig. Das ist ein gutes Konzept angesichts der Tatsache, dass die Hybrid-Cloud derzeit zur Standard-IT-Infrastruktur von Unternehmen wird. Zur weiteren Vereinfachung und Flexibilisierung tragen viele weitere Mechanismen bei. Einige besonders auffällige befassen sich mit der Speicherung und dem Zugriff auf die benötigten Daten.
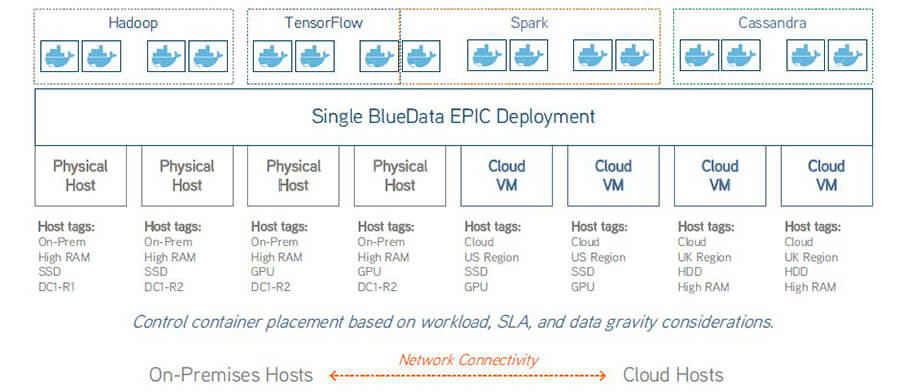 Implementierung von »BlueData« in einer hybriden Multi-Cloud-Umgebung (Grafik: HPE)
Implementierung von »BlueData« in einer hybriden Multi-Cloud-Umgebung (Grafik: HPE)
Docker-Container als Basis
Container heißen im Epic-Kontext virtuelle CPUs (vCPUs) oder Knoten (Nodes), die zu virtuellen Clustern zusammengefasst werden. Die Cluster sind jeweils spezifischen Tenants auf dem Multi-Tenant-fähigen System zugewiesen. Die Epic-Lizenz spezifiziert die Zahl der virtuellen CPU-Cores, die insgesamt von einem Epic-Deployment genutzt werden können. Wie viele das sind, hängt von der Zahl der physischen CPUs auf einem Host und davon ab, wie viele virtuelle CPUs auf einer physischen CPU liegen dürfen. Das wird vom Kunden bei der Implementierung festgelegt. Für vCPUs oder Nodes gibt es drei Größen: klein, mittel und groß. Ein kleiner Knoten beispielsweise besteht aus einer einzigen virtuellen CPU und drei GByte RAM.
Den virtuellen Knoten wird Speicherraum zugewiesen, der sich auf derselben physischen Basis, in EPIC-Terminologie dem Host, befindet. Der Speicherraum ist so groß wie die bei der Installation spezifizierte Root-Disk. Zusätzlich sind bis zu 20 GByte persistente Storage pro Container möglich, was die Containermigration ohne Datenverlust möglich macht. Der Arbeitsspeicher der Nodes befindet sich ebenfalls auf dem Host. RAM-Anteile werden aus den freien Speicher-Ressourcen im Host jedem Tenant im Rahmen der vorhandenen Kapazitäten zugewiesen, die virtuellen Knoten nutzen dann diesen RAM.
Die zu analysierenden Daten, auf die von den Nodes zugegriffen wird, können sich praktisch überall befinden: On-Premises, in der Provider-Cloud, in einer externen, gemanagten Umgebung und so weiter. Sie können an ihrem Standort bleiben, statt wie häufig notwendig zur rechnenden Einheit transportiert zu werden.
Eine Wasserleitung zum Datenpool
Die hier zugrunde liegende Technologie heißt DataTap. Ein Datatap (»Daten-Wasserhahn«) ist ein mit einem Namen versehener, sicherer Pfad zu einer gemeinsam genutzten Speicher-Ressource, deren Inhalt für Analysen benötigt wird. Tenants können auf solche Ressourcen zugreifen und auf ihnen arbeiten, ohne die Daten zu transferieren, indem sie den Namen des für sie angelegten Pfades zu der betreffenden Ressource eingeben. Aktivitäten rund um Spark und Hadoop, beispielsweise Map/Reduce, nutzen dafür einen Unified Resource Identifier (URI), der den Namen des Datatap enthält.
Storage wird in verschiedene Klassen differenziert: Tenant Storage (Storage für einen bestimmten Tenant eines Epic-Systems) bezeichnet Ressourcen, auf die alle Knoten des Tenants zugreifen können. Der Tenant Storage Datatap führt zum obersten Verzeichnis der gesamten Tenant-Storge. Node Storage ist der lokale Speicher jedes physischen Hosts innerhalb einer Epic-Installation. Auf dieser lokalen Storage werden die Disk-Volumes jedes Nodes gespeichert. Persistente-Storage für Container befindet sich auf einem externen, persistenten Storage-Pool auf einer Ressource im Hintergrund und wird nicht von Epic gemanagt. Migriert man Epic-Container mit persisteter Storage, bleiben die wichtigsten Container-Verzeichnisse auf jeden Fall dauerhaft erhalten, will man mehr Container-Daten weiterhin verwenden, ist auch das mit Hilfe eines JSON-Metadatenfiles möglich.
Hardware-Optionen und Hochverfügbarkeit
Kunden implementieren Epic laut HPE gern auf Bare-Metal, also ohne Hypervisor. Prinzipiell ist auch die Implementierung auf VMs und damit auf hyperkonvergenten Systemen, die VMs unterstützen, möglich. Allerdings sei das, so HPE, eine eher unübliche Herangehensweise.
Hochverfügbare Konfigurationen brauchen mindestens einen Cluster, der aus einem Controller-Host und einem Shadow-Controller sowie einem Arbiter-System besteht. Controller-Hosts steuern Worker-Hosts, die die Rechenarbeit erledigen. Dabei kann ein Controller-Host gleichzeitig als Worker fungieren. Potentiell ist die Zahl zusätzlicher Worker-Hosts unbegrenzt.
Viele Bestandskunden von Bluedata dürften derzeit Systeme von Dell EMC nutzen, da Bluedata diesen Hardware-Anbieter bisher als Fachhandel genutzt hat. HPE, über dessen Channel Bluedata in Zukunft vertrieben wird, will seinen Kunden für anwendungsspezifische Zwecke unterschiedliche Hardware-Optionen anbieten, zum Beispiel seine Apollo-Plattform, Memory-Driven- oder mit vielen GPUs ausgerüstete Systeme. Die Plattform ist aber grundsätzlich Hardware-unabhängig. Der Einstiegspreis macht klar, dass die Lösung eher für große Unternehmen gedacht ist. Er liegt zwischen 250.000 und 500.000 US-Dollar.