
Entscheidungshilfe: Das richtige Storage für Proxmox VE
 Proxmox VE ist eine Open-Source-basierte Virtualisierungs-Software, die seit etwa 2023 rasant an Beliebtheit gewonnen hat. Der Einstieg gestaltet sich dank eines intuitiven Web-UI leicht. Dabei gibt es gibt viele Möglichkeiten, Storage Lösungen anzubinden oder Software-Defined Storage anzulegen und zu verwenden. Wir zeigen, welche Storage-Lösung zu welchem Anwendungsfall passt.
Proxmox VE ist eine Open-Source-basierte Virtualisierungs-Software, die seit etwa 2023 rasant an Beliebtheit gewonnen hat. Der Einstieg gestaltet sich dank eines intuitiven Web-UI leicht. Dabei gibt es gibt viele Möglichkeiten, Storage Lösungen anzubinden oder Software-Defined Storage anzulegen und zu verwenden. Wir zeigen, welche Storage-Lösung zu welchem Anwendungsfall passt.
Wer in die Welt von Proxmox VE (PVE) eintauchen möchte, wird sich auch Gedanken zur Storage-Auswahl machen. Zwischen den verfügbaren Storages wird wie folgt grundsätzlich unterschieden: Welche Architekturmodelle sind nutzbar, also file- oder blockbasiert, oder beides; kann das Storage für Cluster, für mehrere Hosts bereitgestellt werden, ist es geteilt oder repliziert verfügbar (Shared-Storage); können virtuelle Ressourcen nach Ablage auf dieses Storage gesnapshottet werden, oder werden Snapshots eingeschränkt / gar nicht unterstützt?
Daraus resultieren zwei weitere Fragen: Möchte ich den Host später als Cluster-Member verwenden, oder wird der Singlehost immer ein Einzel-System bleiben? Und falls die Entscheidung zu einem Cluster-System oder einem zukünftigen Einsatz innerhalb eines Clusters getroffen wurde: Muss/möchte ich ein Shared-Storage verwenden, das zum Beispiel auf iSCSI, NFS, Fibre-Channel (FC) oder NVMe Over TCP setzt? Oder wäre Ceph im Zusammenspiel mit einer Hyper-Converged-Infrastructure (HCI) die bessere Alternative?
Cluster-Perspektive & Storage-Strategie: Weichenstellung bei der Hardware-Wahl
Zu Frage 1: Relevant in dieser Hinsicht ist vor allem die Auswahl der Hardware – wird beispielsweise ein Server-System mit RAID-Controller verwendet, ist für dieses System ein HCI-Setup mit ZFS (Single-Node) oder Ceph (ab 3-Node-Cluster) ausgeschlossen: Beide Lösungen unterstützen keine RAID-Controller bzw. verbieten diese ausdrücklich. So ist bei der Auswahl der ersten Nodes schon mehr oder weniger gesetzt, ob diese Node jemals Teil eines HA-Clusters sein wird oder nicht. Bei Unklarheit: Eine Entscheidung zu ZFS mit Einsatz eines Host-Bus-Adapters (HBA) für den ersten Singlehost gibt die Flexibilität, alle Möglichkeiten für künftige Upgrade-Wege offen zu halten.
Tipp: Viele RAID-Controller kann man im Nachhinein in einen HBA-Modus versetzen.
Zu Frage 2: Mit iSCSI sowie allen anderen Storage-Konzepten mit Logical-Unit-Numbers (LUN) – also FC, NVMe-Over-TCP – lassen sich im PVE-Kontext keine Snapshots erstellen. NFS bietet im Zweifel unter Verwendung eines anderen Disk-Formats mit dem Namen »qcow2« die Möglichkeit, Snapshots von solchen Disks zu erstellen – derzeit allerdings nicht über Windows-Server mit virtuellem TPM-Modul. Letztlich fällt Shared-Storage realistisch meist aus dem Rennen, da Snapshotting oft ein zentraler Bestandteil von IT-Prozessen ist und der Wechsel auf Alternativen, etwa Backups statt Snapshots vor einem Upgrade, unerwünscht und/oder zu umständlich ist.
ZFS
Ein häufiges PVE-Storage ist daher das Zettabyte File System (ZFS). Denn es kann sowohl bei PVE-Singlehosts als auch bei einem ZFS-2-Node-Cluster mit asynchroner VM- oder CT-Replikation verwendet werden. Empfohlen für einen produktiven Enterprise-Betrieb ist der Einsatz von Flash-Speicher in Kombination mit RAID-1 oder RAID-10; der Einsatz von RAID-5 und RAID-6 ist aufgrund des negativen Impacts durch die Paritäts-Bildung auf die Storage-Performance nicht die beste Auswahl. Ist die Entscheidung für ein RAID-Level gefallen, sollte in ZFS pro Terabyte Bruttospeicher ein Gigabyte RAM für das SDS eingerechnet werden – zusätzlich zu den geplanten virtuellen Ressourcen wie VMs und Container. Extra CPU-Ressourcen muss man bei modernen Enterprise-Servern nicht miteinrechnen.
ZFS passt auch gut zu 2-Node-Clustern mit einem externen Witness-Host. Bei gleichnamigen Storage-Pools auf Node-1 und Node-2 kann pro virtuelle Ressource ein Replikations-Job angelegt werden, welcher asynchron in definierten Intervallen – z. B. alle fünf Minuten – eine Replikation der Storage-Disks durchführt. Einmal eingerichtet, können VMs und Container auch ins HA-Programm von PVE hinzugefügt werden. Bei Ausfall eines Knotens starten VMs und Container so automatisch auf dem zweiten Server neu; der Storage-Stand entspricht dabei dem letzten stattgefunden Replikations-Jobs. Ein möglicher Storage-Verlust hängt somit davon ab, wie oft asynchron über Replikations-Job repliziert wird.
Bitte bedenken: ZFS skaliert nicht sinnvoll über mehr als zwei Nodes, da ein Replikations-Job immer nur von einem Node zu einem anderen Ziel-Node eingestellt werden kann, nicht aber auf mehrere. Für synchronen Speicher über mehr als zwei Nodes bietet sich Ceph an.
Ceph
Ceph ist eine Open-Source-Storage-Lösung, die in Proxmox VE eine umfangreiche und nutzerfreundliche Integration erfahren hat. Es kann über einen Installations-Wizard der Web-UI vollständig installiert, konfiguriert und über ein eigenes Dashboard administriert werden. Und es ist die richtige Storage-Auswahl für alle, die ein PVE-Cluster mit einem Storage betreiben möchten, das sowohl hyperconverged als auch mit synchronen Storage-Writes arbeitet – ein Muss für ein Enterprise-Storage!
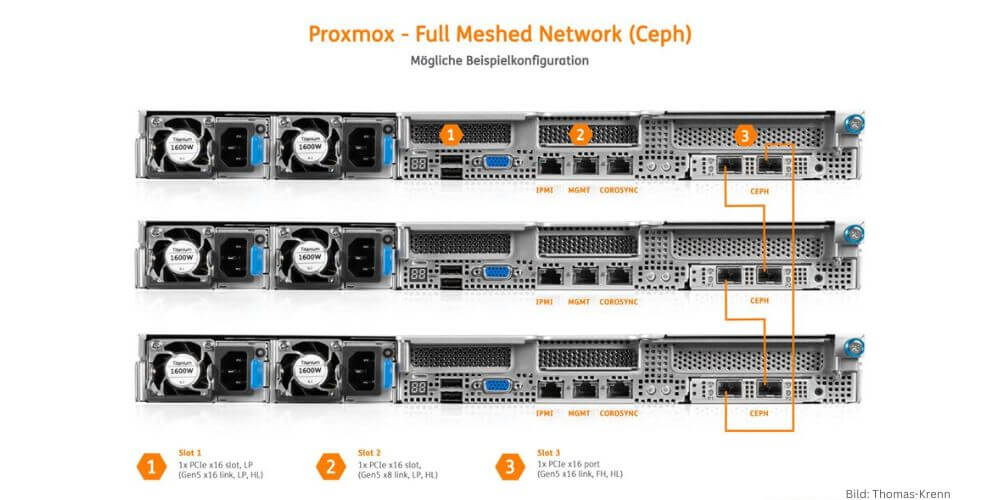 Full Meshed Network für Ceph – mögliche Beispielkonfiguration mit Thomas-Krenn-Servern. (Bild: Thomas-Krenn)
Full Meshed Network für Ceph – mögliche Beispielkonfiguration mit Thomas-Krenn-Servern. (Bild: Thomas-Krenn)
Doch welche Hardware-Anforderungen gibt es zu beachten? Der Regelfall wird der Einsatz einer hyperkonvergenten Infrastruktur sein. Ergänzend zu den Ressourcen für VMs und Container müssen Arbeitsspeicher, CPU, Netzwerk und natürlich Storage-Speicher für Ceph einberechnet werden. Außerdem gibt es eine Mindestanzahl an Nodes. Die Mindestanforderungen in der Übersicht:
- Node-Anzahl: Für die Ablage von mindestens drei Storage-Kopien ist ein Minimum von drei Nodes erforderlich.
- Datenträger: in der Regel NVMe; wenn nicht möglich SATA/SAS-SSDs. HDDs sind nicht performant genug für ein Enterprise-Setup. Pro Node ist es empfehlenswert, mindestens mit vier Datenträgern zu kalkulieren, bei drei Nodes also mindestens zwölf NVMe-SSDs im Gesamtsystem.
- CPU: Ein CPU-Thread pro Datenträger wird empfohlen – bei zum Beispiel vier Datenträgern je Node also vier Threads pro Node.
- Netzwerk: Die Kommunikation wird bei Ceph über das Netzwerk abgewickelt, daher bedeutet ein schnelleres Netzwerk auch ein schnelleres Storage. Deswegen sind Netzwerkkarten mit 25 Gbit/s das empfohlene Minimum, das Optimum sind 100 Gbit/s.
Wer diese Sizing-Rules berücksichtigt hat, kann Ceph nach erfolgreichem Clustering über die Web-UI installieren und im Anschluss dort die erforderlichen Dienste erstellen sowie administrieren. Zuletzt wird ein Storage-Pool angelegt – bei Ceph ist hierbei einer für eine dreifache Datenspeicherung erforderlich (Pool-Parameter: SIZE). Diese drei Kopien werden auf unterschiedliche Nodes geschrieben, bevor der Storage-Client (PVE-Hypervisor) ein Write-Acknowledgement bekommt. Geschriebene Daten sind also sicher und korrekt dreifach abgelegt. Über den Pool-Parameter MIN-SIZE wird außerdem die Anzahl an mindestens vorhandenen Replikaten definiert, damit der Ceph-Pool erreichbar ist. Haben Sie all dies berücksichtigt, steht der Hochverfügbarkeit Ihrer Ressourcen in Proxmox VE nichts mehr im Weg!
Generell gilt noch: Hilfreich ist bei entsprechenden Projekten ein erfahrener Partner, der hochwertige Server-Hardware und umfassendes Proxmox-Know-how vereint. Ein solches Unternehmen ist die Thomas-Krenn.AG, die seit vielen Jahren Proxmox Gold sowie Solution-Partner ist und für Proxmox VE maßgeschneiderte Server-Lösungen entwickelt und liefert – von der Hardware-Auswahl über die Proxmox-Vorinstallation bis hin zu kompletten Cluster-Setups. Die Server sind speziell für den Einsatz mit Proxmox VE konfiguriert und getestet, für maximale Leistung und Stabilität.
Thomas-Krenn.AG
Speltenbach-Steinäcker 1, 94078 Freyung
Tel. 08551/91500
Proxmox optimierte Thomas-Krenn-Systeme