Daten von niedriger Güte sind allgegenwärtig in den Unternehmen. Angefangen bei falschen Entscheidungehn bis hin zu unzuverlässigen Prozessen führen inkorrekte Daten zu Problmen von ungeahnter Größe.
Falsche Artikelnummern, fehlende Werte, unterschiedliche Schreibweisen und Abkürzungen, fehlerhafte Kundendaten und vieles mehr mindern die Datenqualität und führen auf diese Weise zu negativen wirtschaftlichen Folgen, denn das Garbage-in-Garbage-out-Prinzip greift: Fehler in den vorgehaltenen Daten führen zu falschen Entscheidungen, hohen Kosten und unzuverlässigen Prozessen – ein gefährlicher Cocktail, nicht zuletzt auch angesichts der Auswirkungen der globalen Finanzkrise, die vielerorts in der Realwirtschaft bereits spürbar sind. Hilfe aus der Misere bieten Data- Profiling- und -Analysis-Systeme.

ZentralerWettbewerbsvorteil
Mehr und mehr wächst in den Unternehmen die Einsicht, dass qualitativ hochwertige Informationen einen zentralen Wettbewerbsfaktor und den Grundbestandteil vieler IT-Aktivitäten und Geschäftsprozesse darstellen – dies gilt für Kundendaten, im Risikomanagement und bei Business Intelligence (BI)-Initiativen genauso wie bei der Umsetzung von Compliance-Vorgaben. Nur über bestmögliches Datenmaterial lassen sich optimale Ergebnisse, hohe Profitabilität, Kostenreduzierung sowie die Erschließung neuer Umsatz- und Gewinnpotenziale erzielen. Angesichts der ständig wachsenden Fülle an Daten können klassische IT-Systeme die gewünschte Qualität nicht ohne weiteres
gewährleisten. Die Folgen sind schwerwiegend: Durch die Interpretation falscher, irreführender oder nicht aktueller Daten und Informationen, weil Anwender und Nutzer zumrichtigen Zeitpunkt nicht auf die richtigen Informationen zugreifen können oder der Kontext zu anderen Daten schlichtweg fehlt, entstehen beispielsweise hohe Zusatzkosten durch vermeidbare Postrückläufer oderMehrfachaussendungen. Kundenbeziehungen verschlechtern sich aufgrund veralteter, unvollständiger, missverständlicher oder gänzlich falscher Informationen, die gleichzeitig auch nichtmehr als korrekte Grundlage für strategische Entscheidungen unter anderemauf Berichtsebene dienen können. Zu den im Tagesgeschäft aktuell feststellbaren Problemen kommen so möglicherweise langfristige Konsequenzen wie der Verlust der Kundenbeziehung oder gescheiterte Projekte und daraus resultierend bleibende Imageschäden.
Unpräzise Ergebnisse trotz hohen Zeitaufwands
Traditionelle, manuell durchgeführte Analysen, um die gewünschte Qualität der vorgehaltenen Customer- und Non-Customer-Daten sicherzustellen, sind zeitaufwändig und unpräzise, denn sie basieren nicht selten auf Subjektivität und Vermutungen sowie auf unvollständigen oder unkorrekten Daten; vielfach geht die Suche auch nur in Richtung erwarteter Mängel und Inkonsistenzen. Hinzu kommt, dass nur bedingt Spezialisten vor Ort verfügbar sind, die die entscheidende Bedeutung der Daten für die täglichen Prozesse überhaupt kennen, und dass ganz prinzipiell auch ein unterschiedliches Verständnis bei der Geschäftsführung, den Fachbereichen und Technikern darüber besteht, welcheWertigkeit die Datenqualität per se überhaupt im Unternehmen hat.

Daten-Inventur via Data-Profiling
Die Erkenntnis, dass im Unternehmen Probleme hinsichtlich der Datenqualität gegeben sind, ist bereits der erste Schritt – der nächste ist es dann, mit Data Profiling eine „Inventur“ der unternehmensweit verfügbaren Daten vorzunehmen, indem die Struktur, die Beziehungen und der Inhalt der vorhandenen Datenquellen und -strukturen intensiv analysiert werden. Am Ende steht dann ein genauer Ist-Zustand mit verbindlichen Informationen zu Qualität und Beschaffenheit. So leistet Data Profiling auch in der Vorbereitung von Projekten zur Datenmigration, Datenintegration oder im Master Data Management wertvolle Dienste. Auf dieser Basis lassen sich dann realistische Projektpläne entwickeln, die entsprechenden Vorkehrungen zur Bereinigung initiieren und die dafür notwendigen Prozesse managen, um spätere Probleme und Nacharbeiten bei der Projektdurchführung zu vermeiden.
Effizientes Problem-Management
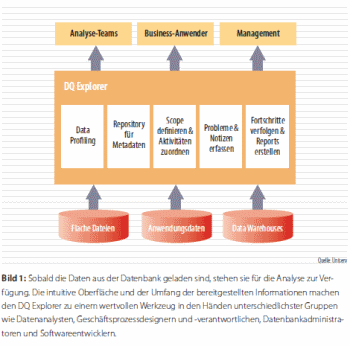
Innerhalb eines kompletten und durchgängigen Data Quality Life Cycles aus Profiling & Analysis, Data Cleansing, Firewall und Monitoring bietet beispielsweise die Uniserv GmbHmit dem DQ Explorer ein interaktives Data-Profiling- und -Analysis-System für eine umfassende Bestandsaufnahme von Customer- und Businessdaten an. Damit erhalten Entscheider, Datenanalysten, Softwareentwickler und Datenbankadministratoren jederzeit und auf einen Blick einen genauen und detaillierten Überblick über den Zustand der im Unternehmen vorgehaltenen Daten. Durch vielfältige Funktionen liefert das Tool in wenigen Schritten automatisch einen schnellen, genauen und
detaillierten Überblick über den jeweiligen Datenzustand.
Um die aus der Analyse gewonnenen Erkenntnisse zur Verbesserung der Datenqualität effizient zu nutzen, sind weitere Funktionalitäten zum Aufsetzen und Verfolgen entsprechender Projekte und zur Vermeidung späterer Konflikte und Nacharbeiten verfügbar. So lassen sich beispielsweise die ermittelten Probleme den jeweiligenMitarbeitern über eine E-Mail-Alert-Option zuordnen und die Fortschritte überwachen.

Eines für alles in einer Anwendung
Mit dem Einsatz des DQ Explorers entfällt die bislang praktizierte Vorgehensweise, bei der Analyseprojekte eine Vielzahl von Toolsets durchlaufen müssen, denn die verschiedenen Schritte werden integriert in einer einzigen Anwendung gemanagt. Dabei ermitteln die Anwender mit einer intuitiv gestalteten Oberfläche imRahmen einer automatisierten Quelldatenanalyse den Ist-Zustand der Daten sowie bestehende Fehler, Anomalien und Inkonsistenzen. Dies kann vor einer Überführung in andere Systeme, im Rahmen von Compliance- und BI-Initiativen oder auch bei Migrations-, Balanced-Scorecard- oder Data-Warehouse-Projekten geschehen. Das Profiling-Tool liefert automatisch für jedes Attribut Informationen wie beispielsweise Werte und Muster sowie deren Häufigkeit, Anteil Null-Werte, Anteil eindeutiger Werte, Minimum und Maximum, abgeleiteter Datentyp oder auch Verdacht auf Ausreißer. Auffällige und problematische Werte können umgehend erkannt und die betroffenen Datensätze per Mausklick angezeigt werden; auch Join-Prüfungen zwischen Tabellen aus unterschiedlichen Datenquellen sind möglich. Im Ergebnis lässt sich so eine Zeitersparnis von bis zu 90 Prozent im Vergleich zu herkömmlichenMethoden erzielen.
Roland Pfeiffer
Diesen Artikel finden Sie auch in der April-Ausgabe des it managements.